Each RX filter table contains filters with two different levels of
specificity: TCP/IPv4 and UDP/IPv4 filters match the local address and
port and optionally the remote address and port; Ethernet filters
match the local address and optionally the VID. The more specific
filters always override less specific filters within the same table,
and should be numbered accordingly.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
This filter flag cannot yet be set through the ethtool command and
will not be supported on future hardware.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
The loopback self-test iterates over all the TX queues of channel 0,
which is not very interesting when that's an RX-only channel.
Signed-off-by: Ben Hutchings <bhutchings@solarflre.com>
The least significant bit number (LBN) of a field within an MCDI
structure is counted from the start of the structure, not the
containing dword. In MCDI_ARRAY_FIELD() we need to mask it rather
than using the usual EFX_DWORD_FIELD() macro.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
Commit c31e5f9 ('sfc: Add channel specific receive_skb handler and
post_remove callback') added the function pointer field
efx_channel_type::post_remove and an unconditional call through it.
This field should have been initialised to efx_channel_dummy_op_void
in the existing instances of efx_channel_type, but this was only done
in efx_default_channel_type. Consequently, if a device has SR-IOV
enabled then removing the driver or device will result in an oops.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
Since (9f00d97 netlink: hide struct module parameter in netlink_kernel_create),
linux/netlink.h includes linux/module.h because of the use of THIS_MODULE.
Use linux/export.h instead, as suggested by Stephen Rothwell, which is
significantly smaller and defines THIS_MODULES.
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Commit eb716c54b1 ("sunbmac: remove
unnecessary setting of skb->dev") caused the local varible 'dev'
in bigmac_init_rings to become unused. And now the compiler
warns about it.
Signed-off-by: David S. Miller <davem@davemloft.net>
On some hw, link is not up during adding iface to team. That causes event
not being sent to userspace and that may cause confusion.
Fix this bug by sending port changed event once it's added to team.
Signed-off-by: Jiri Pirko <jiri@resnulli.us>
Signed-off-by: David S. Miller <davem@davemloft.net>
On small systems (e.g. embedded ones) IP addresses are often configured
by bootloaders and get assigned to kernel via parameter "ip=". If set to
"ip=dhcp", even nameserver entries from DHCP daemons are handled. These
entries exported in /proc/net/pnp are commonly linked by /etc/resolv.conf.
To configure nameservers for networks without DHCP, this patch adds option
<dns0-ip> and <dns1-ip> to kernel-parameter 'ip='.
Signed-off-by: Christoph Fritz <chf.fritz@googlemail.com>
Tested-by: Jan Weitzel <j.weitzel@phytec.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
One of the modes of Huawei E367 has this QMI/wwan interface:
I:* If#= 1 Alt= 0 #EPs= 3 Cls=ff(vend.) Sub=01 Prot=07 Driver=(none)
E: Ad=83(I) Atr=03(Int.) MxPS= 64 Ivl=2ms
E: Ad=84(I) Atr=02(Bulk) MxPS= 512 Ivl=0ms
E: Ad=02(O) Atr=02(Bulk) MxPS= 512 Ivl=4ms
Huawei use subclass and protocol to identify vendor specific
functions, so adding a new vendor rule for this combination.
The Pantech devices UML290 (106c:3718) and P4200 (106c:3721) use
the same subclass to identify the QMI/wwan function. Replace the
existing device specific UML290 entries with generic vendor matching,
adding support for the Pantech P4200.
The ZTE MF683 has 6 vendor specific interfaces, all using
ff/ff/ff for cls/sub/prot. Adding a match on interface #5 which
is a QMI/wwan interface.
Cc: Fangxiaozhi (Franko) <fangxiaozhi@huawei.com>
Cc: Thomas Schäfer <tschaefer@t-online.de>
Cc: Dan Williams <dcbw@redhat.com>
Cc: Shawn J. Goff <shawn7400@gmail.com>
Signed-off-by: Bjørn Mork <bjorn@mork.no>
Signed-off-by: David S. Miller <davem@davemloft.net>
When CONFIG_IPV6=m and CONFIG_L2TP=y, I got the following compile error:
LD init/built-in.o
net/built-in.o: In function `l2tp_xmit_core':
l2tp_core.c:(.text+0x147781): undefined reference to `inet6_csk_xmit'
net/built-in.o: In function `l2tp_tunnel_create':
(.text+0x149067): undefined reference to `udpv6_encap_enable'
net/built-in.o: In function `l2tp_ip6_recvmsg':
l2tp_ip6.c:(.text+0x14e991): undefined reference to `ipv6_recv_error'
net/built-in.o: In function `l2tp_ip6_sendmsg':
l2tp_ip6.c:(.text+0x14ec64): undefined reference to `fl6_sock_lookup'
l2tp_ip6.c:(.text+0x14ed6b): undefined reference to `datagram_send_ctl'
l2tp_ip6.c:(.text+0x14eda0): undefined reference to `fl6_sock_lookup'
l2tp_ip6.c:(.text+0x14ede5): undefined reference to `fl6_merge_options'
l2tp_ip6.c:(.text+0x14edf4): undefined reference to `ipv6_fixup_options'
l2tp_ip6.c:(.text+0x14ee5d): undefined reference to `fl6_update_dst'
l2tp_ip6.c:(.text+0x14eea3): undefined reference to `ip6_dst_lookup_flow'
l2tp_ip6.c:(.text+0x14eee7): undefined reference to `ip6_dst_hoplimit'
l2tp_ip6.c:(.text+0x14ef8b): undefined reference to `ip6_append_data'
l2tp_ip6.c:(.text+0x14ef9d): undefined reference to `ip6_flush_pending_frames'
l2tp_ip6.c:(.text+0x14efe2): undefined reference to `ip6_push_pending_frames'
net/built-in.o: In function `l2tp_ip6_destroy_sock':
l2tp_ip6.c:(.text+0x14f090): undefined reference to `ip6_flush_pending_frames'
l2tp_ip6.c:(.text+0x14f0a0): undefined reference to `inet6_destroy_sock'
net/built-in.o: In function `l2tp_ip6_connect':
l2tp_ip6.c:(.text+0x14f14d): undefined reference to `ip6_datagram_connect'
net/built-in.o: In function `l2tp_ip6_bind':
l2tp_ip6.c:(.text+0x14f4fe): undefined reference to `ipv6_chk_addr'
net/built-in.o: In function `l2tp_ip6_init':
l2tp_ip6.c:(.init.text+0x73fa): undefined reference to `inet6_add_protocol'
l2tp_ip6.c:(.init.text+0x740c): undefined reference to `inet6_register_protosw'
net/built-in.o: In function `l2tp_ip6_exit':
l2tp_ip6.c:(.exit.text+0x1954): undefined reference to `inet6_unregister_protosw'
l2tp_ip6.c:(.exit.text+0x1965): undefined reference to `inet6_del_protocol'
net/built-in.o:(.rodata+0xf2d0): undefined reference to `inet6_release'
net/built-in.o:(.rodata+0xf2d8): undefined reference to `inet6_bind'
net/built-in.o:(.rodata+0xf308): undefined reference to `inet6_ioctl'
net/built-in.o:(.data+0x1af40): undefined reference to `ipv6_setsockopt'
net/built-in.o:(.data+0x1af48): undefined reference to `ipv6_getsockopt'
net/built-in.o:(.data+0x1af50): undefined reference to `compat_ipv6_setsockopt'
net/built-in.o:(.data+0x1af58): undefined reference to `compat_ipv6_getsockopt'
make: *** [vmlinux] Error 1
This is due to l2tp uses symbols from IPV6, so when IPV6
is a module, l2tp is not allowed to be builtin.
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Jeff Kirsher says:
====================
This series contains updates to igb and ixgbevf.
v2: updated patch description in 04 patch (ixgbevf: scheduling while
atomic in reset hw path)
...
Akeem G. Abodunrin (1):
igb: Support to enable EEE on all eee_supported devices
Alexander Duyck (2):
igb: Remove artificial restriction on RQDPC stat reading
ixgbevf: Add support for VF API negotiation
John Fastabend (1):
ixgbevf: scheduling while atomic in reset hw path
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
Remove unnecessary temporary variable and #ifdef DEBUG block.
Signed-off-by: Joe Perches <joe@perches.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
The dbg() USB macro is so old, it predates me. The USB networking drivers are
the last hold-out using this macro, and we want to get rid of it, so replace
the usage of it with the proper netdev_dbg() or dev_dbg() (depending on the
context) calls.
Some places we end up using a local variable for the debug call, so also
convert the other existing dev_* calls to use it as well, to save tiny amounts
of code space.
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Both tcp_timewait_state_process and tcp_check_req use the same basic
construct of
struct tcp_options received tmp_opt;
tmp_opt.saw_tstamp = 0;
then call
tcp_parse_options
However if they are fed a frame containing a TCP_SACK then tbe code
behaviour is undefined because opt_rx->sack_ok is undefined data.
This ought to be documented if it is intentional.
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Christoph Paasch <christoph.paasch@uclouvain.be>
Acked-by: H.K. Jerry Chu <hkchu@google.com>
Acked-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Add rtnl_link_ops to IPoIB, with the first usage being child device
create/delete through them. Childs devices are now either legacy ones,
created/deleted through the ipoib sysfs entries, or RTNL ones.
Adding support for RTNL childs involved refactoring of ipoib_vlan_add
which is now used by both the sysfs and the link_ops code.
Also, added ndo_uninit entry to support calling unregister_netdevice_queue
from the rtnl dellink entry. This required removal of calls to
ipoib_dev_cleanup from the driver in flows which use unregister_netdevice,
since the networking core will invoke ipoib_uninit which does exactly that.
Signed-off-by: Erez Shitrit <erezsh@mellanox.co.il>
Signed-off-by: Or Gerlitz <ogerlitz@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Ben Hutchings says:
====================
1. Extension to PPS/PTP to allow for PHC devices where pulses are
subject to a variable but measurable delay.
2. PPS/PTP/PHC support for Solarflare boards with a timestamping
peripheral.
3. MTD support for updating the timestamping peripheral on those boards.
4. Fix for potential over-length requests to firmware.
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
This change makes it so that the VF can support the PF/VF API negotiation
protocol. Specifically in this case we are adding support for API 1.0
which will mean that the VF is capable of cleaning up buffers that span
multiple descriptors without triggering an error.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Sibai Li <sibai.li@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Current implementation enables EEE on only i350 device. This patch enables
EEE on all eee_supported devices. Also, configured LPI clock to keep
running before EEE is enabled on i210 and i211 devices.
Signed-off-by: Akeem G. Abodunrin <akeem.g.abodunrin@intel.com>
Tested-by: Jeff Pieper <jeffrey.e.pieper@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
For some reason the reading of the RQDPC register was being artificially
limited to 4K. Instead of limiting the value we should read the value and
add the full amount. Otherwise this can lead to a misleading number of
dropped packets when the actual value is in fact much higher.
Signed-off-by: Alexander Duyck <alexander.h.duyck@intel.com>
Tested-by: Jeff Pieper <jeffrey.e.pieper@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
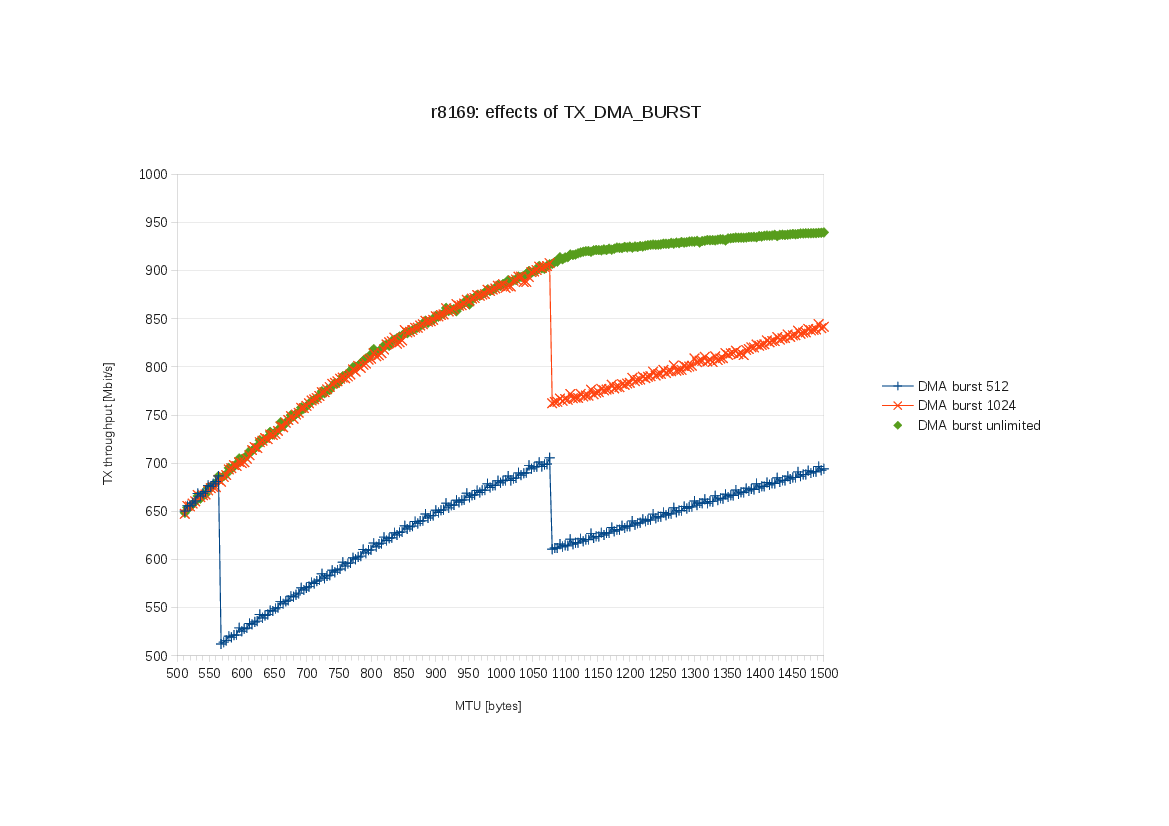
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Two years ago, Shan Wei tried to fix this:
http://patchwork.ozlabs.org/patch/43905/
The problem is that RFC2460 requires an ICMP Time
Exceeded -- Fragment Reassembly Time Exceeded message should be
sent to the source of that fragment, if the defragmentation
times out.
"
If insufficient fragments are received to complete reassembly of a
packet within 60 seconds of the reception of the first-arriving
fragment of that packet, reassembly of that packet must be
abandoned and all the fragments that have been received for that
packet must be discarded. If the first fragment (i.e., the one
with a Fragment Offset of zero) has been received, an ICMP Time
Exceeded -- Fragment Reassembly Time Exceeded message should be
sent to the source of that fragment.
"
As Herbert suggested, we could actually use the standard IPv6
reassembly code which follows RFC2460.
With this patch applied, I can see ICMP Time Exceeded sent
from the receiver when the sender sent out 3/4 fragmented
IPv6 UDP packet.
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Cc: Hideaki YOSHIFUJI <yoshfuji@linux-ipv6.org>
Cc: Patrick McHardy <kaber@trash.net>
Cc: Pablo Neira Ayuso <pablo@netfilter.org>
Cc: netfilter-devel@vger.kernel.org
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
As pointed by Michal, it is necessary to add a new
namespace for nf_conntrack_reasm code, this prepares
for the second patch.
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Michal Kubeček <mkubecek@suse.cz>
Cc: David Miller <davem@davemloft.net>
Cc: Patrick McHardy <kaber@trash.net>
Cc: Pablo Neira Ayuso <pablo@netfilter.org>
Cc: netfilter-devel@vger.kernel.org
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
In netpoll tx path, we miss the chance of calling ->ndo_select_queue(),
thus could cause problems when bonding is involved.
This patch makes dev_pick_tx() extern (and rename it to netdev_pick_tx())
to let netpoll call it in netpoll_send_skb_on_dev().
Reported-by: Sylvain Munaut <s.munaut@whatever-company.com>
Cc: "David S. Miller" <davem@davemloft.net>
Cc: Eric Dumazet <edumazet@google.com>
Signed-off-by: Cong Wang <amwang@redhat.com>
Tested-by: Sylvain Munaut <s.munaut@whatever-company.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
The internal functions for add/deleting addresses don't change
their argument.
Signed-off-by: Stephen Hemminger <shemminger@vyatta.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
When building 64-bit kernel with this driver we get following warnings from
the compiler:
drivers/net/ethernet/i825xx/znet.c: In function ‘hardware_init’:
drivers/net/ethernet/i825xx/znet.c:863:29: warning: cast from pointer to integer of different size [-Wpointer-to-int-cast]
drivers/net/ethernet/i825xx/znet.c:870:29: warning: cast from pointer to integer of different size [-Wpointer-to-int-cast]
Fix these by calling isa_virt_to_bus() before passing the pointers to
set_dma_addr().
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Add GSO support to GRE tunnels.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Maciej Żenczykowski <maze@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Instead of forcing device drivers to provide empty ethtool_ops or tweak
net/core/ethtool.c again, we could provide a generic ethtool_ops.
This occurred to me when I wanted to add GSO support to GRE tunnels.
ethtool -k support should be generic for all drivers.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Ben Hutchings <bhutchings@solarflare.com>
Cc: Maciej Żenczykowski <maze@google.com>
Reviewed-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
When moving a nic from net namespace A to net namespace B,
in dev_change_net_namesapce,we call __dev_get_by_name to
decide if the netns B has the device has the same name.
if the netns B already has the same named device,we call
dev_get_valid_name to try to get a valid name for this nic in
the netns B,but net_device->nd_net still point to netns A now.
this patch fix it.
Signed-off-by: Gao feng <gaofeng@cn.fujitsu.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
If dst cache dst_a copies from dst_b, and dst_b copies from dst_c, check
if dst_a is expired or not, we should not end with dst_a->dst.from, dst_b,
we should check dst_c.
CC: Gao feng <gaofeng@cn.fujitsu.com>
Signed-off-by: Li RongQing <roy.qing.li@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
dev_queue_xmit_nit() should be called right before ndo_start_xmit()
calls or we might give wrong packet contents to taps users :
Packet checksum can be changed, or packet can be linearized or
segmented, and segments partially sent for the later case.
Also a memory allocation can fail and packet never really hit the
driver entry point.
Reported-by: Jamie Gloudon <jamie.gloudon@gmail.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
MCDI supports requests up to 252 bytes long, which is only enough to
pass 63 RX queue IDs to MC_CMD_FLUSH_RX_QUEUES. However a VF may have
up to 64 RX queues, and if we try to flush them all we will generate
an over-length request and BUG() in efx_mcdi_copyin(). Currently
all VF drivers limit themselves to 32 RX queues, so reducing the
limit to 63 does no harm.
Also add a BUILD_BUG_ON in efx_mcdi_flush_rxqs() so we remember to
deal with the same problem there if EFX_MAX_CHANNELS is increased.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
On big-endian systems the MTD partition names currently have mangled
subtype numbers and are not recognised by the firmware update tool
(sfupdate).
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
Add PTP IEEE-1588 support and make accesible via the PHC subsystem.
This work is based on prior code by Andrew Jackson
Signed-off-by: Stuart Hodgson <smhodgson@solarflare.com>
[bwh:
- Add byte order conversion in efx_ptp_send_times()
- Simplify conversion of PPS event times
- Add the built-in vs module check to CONFIG_SFC_PTP dependencies]
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
The maximum array sizes have been calculated on the basis of a maximum
SDU size of 255 bytes, whereas the actual maximum is 252 bytes.
Constructing a larger SDU will result in a BUG_ON in efx_mcdi_copyin.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
These arrays are accessed by iteration in
llc_exec_station_trans_actions(). There must not be any zero-filled
gaps in them, so the explicit indices are pointless.
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: David S. Miller <davem@davemloft.net>
We only ever put one skb on the send queue, and then immediately
send it. Remove the queue and call dev_queue_xmit() directly.
This leaves struct llc_station empty, so remove that as well.
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: David S. Miller <davem@davemloft.net>
{kind=link}