The calculation of the full allocated memory did not take
into account the size of the base hash bucket structure at some
places.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
The set full case (with net_ratelimit()-ed pr_warn()) is already
handled, simply jump there.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Before this patch struct htype created at the first source
of ip_set_hash_gen.h and it is common for both IPv4 and IPv6
set variants.
Make struct htype per ipset family and use NLEN to make
nets array fixed size to simplify struct htype allocation.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Exit as easly as possible on error and use RCU_INIT_POINTER()
as set is not seen at creation time.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Data for hashing required to be array of u32. Make sure that
element data always multiple of u32.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Hash types define HOST_MASK before inclusion of ip_set_hash_gen.h
and the only place where NLEN needed to be calculated at runtime
is *_create() method.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Remove one leve of intendation by using continue while
iterating over elements in bucket.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Remove redundant parameters nets_length and dsize, because
they can be get from other parameters.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Non-static (i.e. comment) extension was not counted into the memory
size. A new internal counter is introduced for this. In the case of
the hash types the sizes of the arrays are counted there as well so
that we can avoid to scan the whole set when just the header data
is requested.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
It is better to list the set elements for all set types, thus the
header information is uniform. Element counts are therefore added
to the bitmap and list types.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
It would be useful for userspace to query the size of an ipset hash,
however, this data is not exposed to userspace outside of counting the
number of member entries. This patch uses the attribute
IPSET_ATTR_ELEMENTS to indicate the size in the the header that is
exported to userspace. This field is then printed by the userspace
tool for hashes.
Signed-off-by: Eric B Munson <emunson@akamai.com>
Cc: Pablo Neira Ayuso <pablo@netfilter.org>
Cc: Josh Hunt <johunt@akamai.com>
Cc: netfilter-devel@vger.kernel.org
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Cleanup: group ip_set_put_extensions and ip_set_get_extensions
together and add missing extern.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Hash types already has it's memsize calculation code in separate
functions. Clean up and do the same for *bitmap* and *list* sets.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Suggested-by: Sergey Popovich <popovich_sergei@mail.ua>
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Cleanup to separate all extensions into individual files.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Suggested-by: Sergey Popovich <popovich_sergei@mail.ua>
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Allocate memory with kmalloc() rather than kzalloc(): the string
is immediately initialized so it is unnecessary to zero out
the allocated memory area.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Suggested-by: Sergey Popovich <popovich_sergei@mail.ua>
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Use struct ip_set_skbinfo in struct ip_set_ext instead of open
coded fields and assign structure members in get/init helpers
instead of copying members one by one. Explicitly note that
struct ip_set_skbinfo must be padded to prevent non-aligned
access in the extension blob.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Suggested-by: Sergey Popovich <popovich_sergei@mail.ua>
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Mark some of the helpers arguments as const.
Ported from a patch proposed by Sergey Popovich <popovich_sergei@mail.ua>.
Suggested-by: Sergey Popovich <popovich_sergei@mail.ua>
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
The TIOCMIWAIT implementation would return -EINVAL if any of the three
supported signals were included in the mask.
Instead of returning an error in case TIOCM_CTS is included, simply
drop the mask check completely, which is in accordance with how other
drivers implement this ioctl.
Fixes: 5a6a62bdb9 ("cdc-acm: add TIOCMIWAIT")
Cc: stable <stable@vger.kernel.org>
Signed-off-by: Johan Hovold <johan@kernel.org>
Acked-by: Oliver Neukum <oneukum@suse.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
After commit 6ed46d1247 ("sock_diag: align nlattr properly when
needed"), tcp_get_info() gets 64bit aligned memory, so we can avoid
the unaligned helpers.
Suggested-by: David Miller <davem@davemloft.net>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Acked-by: Soheil Hassas Yeganeh <soheil@google.com>
Acked-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Lorenzo noted an Android unit test failed due to e0d56fdd73:
"The expectation in the test was that the RST replying to a SYN sent to a
closed port should be generated with oif=0. In other words it should not
prefer the interface where the SYN came in on, but instead should follow
whatever the routing table says it should do."
Revert the change to ip_send_unicast_reply and tcp_v6_send_response such
that the oif in the flow is set to the skb_iif only if skb_iif is an L3
master.
Fixes: e0d56fdd73 ("net: l3mdev: remove redundant calls")
Reported-by: Lorenzo Colitti <lorenzo@google.com>
Signed-off-by: David Ahern <dsa@cumulusnetworks.com>
Tested-by: Lorenzo Colitti <lorenzo@google.com>
Acked-by: Lorenzo Colitti <lorenzo@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
- netlink and code cleanups by Sven Eckelmann (3 patches)
- Cleanup and minor fixes by Linus Luessing (3 patches)
- Speed up multicast update intervals, by Linus Luessing
- Avoid (re)broadcast in meshes for some easy cases,
by Linus Luessing
- Clean up tx return state handling, by Sven Eckelmann (6 patches)
- Fix some special mac address handling cases, by Sven Eckelmann
(3 patches)
-----BEGIN PGP SIGNATURE-----
iQIzBAABCgAdBQJYI6GFFhxzd0BzaW1vbnd1bmRlcmxpY2guZGUACgkQoSvjmEKS
nqHyEw/9GkYNRQJOk1JMuW0cDvj9uWqoendvXRNPVkCvqh4gjX4o+aQaeyumv1/v
eYqpslQWmSsrIlGQ6UGCegzyzZ7jXo6ZijM7wvz2bWwB2C0NzUGlBBCzOeA6Bui/
3Fq+Xmx0Xcf5+c82YmrLor/yYp4FIFTao4+a80vHzQeI/Hg8RuJTOFJdtVNV3JPP
VrfzMAPLLXJPPKHjt1PN3lfANWqX6nWLUMhHBNkMpYB+mMdyaCve6X+MxPF+WYBH
wBO8spU35chW7dp8HOncof5nRDv2xVHWs6TN2kdJ762YrZ1oL0GXwWXViKhWskSQ
QEeOLboyj3IuwPsxOQOLQEbAMrp6jqj3L/6lYWRkV2U6Bbi8EYdozW8L3utxMcvA
Dft8D2U5JAD5ja0VUFyGhwNaBFien2B9JSEwsyOLtUbaQSASNyvym75WrN2Ey/d7
JhBzUt6Iwh8RNJylY3nG5OkoNnyXYv3VrQLsIW4QTHc8Um9eaiOeFHtuAi6WNBtI
HgMwPcdErNbmPd3w9OM6kk6aBQ/DTUK/7CNUKYVoGDayGxKYGDwqhoog9zm18wrt
wc/TtdIY+q95hgm8fDCJefrnkaIxDJrVtChs30N/pJ24MeKcHuibop3HzxIngze2
zPZTuXRKA2VSt79+EV4KORAutexi1WQIN7nRH1a8zMsYfyMKG8Y=
=1xrj
-----END PGP SIGNATURE-----
Merge tag 'batadv-next-for-davem-20161108-v2' of git://git.open-mesh.org/linux-merge
Simon Wunderlich says:
====================
pull request for net-next: batman-adv 2016-11-08 v2
This feature and cleanup patchset includes the following changes:
- netlink and code cleanups by Sven Eckelmann (3 patches)
- Cleanup and minor fixes by Linus Luessing (3 patches)
- Speed up multicast update intervals, by Linus Luessing
- Avoid (re)broadcast in meshes for some easy cases,
by Linus Luessing
- Clean up tx return state handling, by Sven Eckelmann (6 patches)
- Fix some special mac address handling cases, by Sven Eckelmann
(3 patches)
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
Add support for Cypress GX3 SuperSpeed to Gigabit Ethernet
Bridge Controller (Vendor=04b4 ProdID=3610).
Patch verified on x64 linux kernel 4.7.4, 4.8.6, 4.9-rc4 systems
with the Kensington SD4600P USB-C Universal Dock with Power,
which uses the Cypress GX3 SuperSpeed to Gigabit Ethernet Bridge
Controller.
A similar patch was signed-off and tested-by Allan Chou
<allan@asix.com.tw> on 2015-12-01.
Allan verified his similar patch on x86 Linux kernel 4.1.6 system
with Cypress GX3 SuperSpeed to Gigabit Ethernet Bridge Controller.
Tested-by: Allan Chou <allan@asix.com.tw>
Tested-by: Chris Roth <chris.roth@usask.ca>
Tested-by: Artjom Simon <artjom.simon@gmail.com>
Signed-off-by: Allan Chou <allan@asix.com.tw>
Signed-off-by: Chris Roth <chris.roth@usask.ca>
Signed-off-by: David S. Miller <davem@davemloft.net>
Richard Cochran says:
====================
PHC frequency fine tuning
This series expands the PTP Hardware Clock subsystem by adding a
method that passes the frequency tuning word to the the drivers
without dropping the low order bits. Keeping those bits is useful for
drivers whose frequency resolution is higher than 1 ppb.
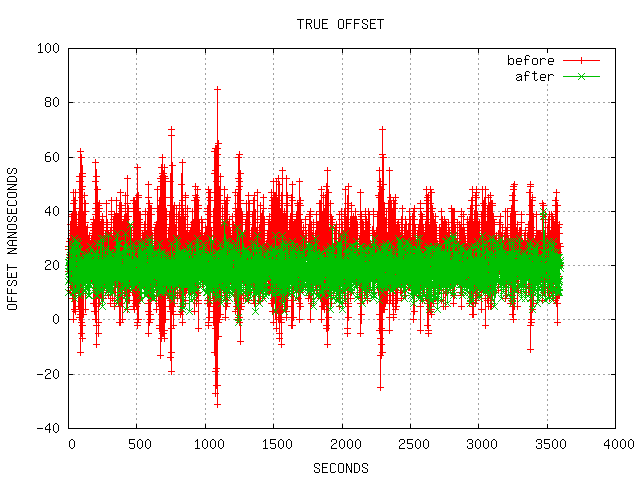
The appended script (below) runs a simple demonstration of the
improvement. This test needs two Intel i210 PCIe cards installed in
the same PC, with their SDP0 pins connected by copper wire. Measuring
the estimated offset (from the ptp4l servo) and the true offset (from
the PPS) over one hour yields the following statistics.
| | Est. Before | Est. After | True Before | True After |
|--------+---------------+---------------+---------------+---------------|
| min | -5.200000e+01 | -1.600000e+01 | -3.100000e+01 | -1.000000e+00 |
| max | +5.700000e+01 | +2.500000e+01 | +8.500000e+01 | +4.000000e+01 |
| pk-pk: | +1.090000e+02 | +4.100000e+01 | +1.160000e+02 | +4.100000e+01 |
| mean | +6.472222e-02 | +1.277778e-02 | +2.422083e+01 | +1.826083e+01 |
| stddev | +1.158006e+01 | +4.581982e+00 | +1.207708e+01 | +4.981435e+00 |
Here the numbers in units of nanoseconds, and the ~20 nanosecond PPS
offset is due to input/output delays on the i210's external interface
logic.
With the series applied, both the peak to peak error and the standard
deviation improve by a factor of more than two. These two graphs show
the improvement nicely.
http://linuxptp.sourceforge.net/fine-tuning/fine-est.pnghttp://linuxptp.sourceforge.net/fine-tuning/fine-tru.png
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
The dp83640 has a frequency resolution of about 0.029 ppb.
This patch lets users of the device benefit from the
increased frequency resolution when tuning the clock.
Signed-off-by: Richard Cochran <richardcochran@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
The 82580 and related devices offer a frequency resolution of about
0.029 ppb. This patch lets users of the device benefit from the
increased frequency resolution when tuning the clock.
Signed-off-by: Richard Cochran <richardcochran@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
The internal PTP Hardware Clock (PHC) interface limits the resolution for
frequency adjustments to one part per billion. However, some hardware
devices allow finer adjustment, and making use of the increased resolution
improves synchronization measurably on such devices.
This patch adds an alternative method that allows finer frequency tuning
by passing the scaled ppm value to PHC drivers. This value comes from
user space, and it has a resolution of about 0.015 ppb. We also deprecate
the older method, anticipating its removal once existing drivers have been
converted over.
Signed-off-by: Richard Cochran <richardcochran@gmail.com>
Suggested-by: Ulrik De Bie <ulrik.debie-os@e2big.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
There are no more users except from net/core/dev.c
napi_hash_add() can now be static.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Michael Chan <michael.chan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This is automatically done from netif_napi_add(), and we want to not
export napi_hash_add() anymore in the following patch.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Michael Chan <michael.chan@broadcom.com>
Acked-by: Michael Chan <michael.chan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Remove the unused but set variables min_set and max_set in
adjust_reg_min_max_vals to fix the following warning when building with
'W=1':
kernel/bpf/verifier.c:1483:7: warning: variable ‘min_set’ set but not used [-Wunused-but-set-variable]
There is no warning about max_set being unused, but since it is only
used in the assignment of min_set it can be removed as well.
They were introduced in commit 484611357c ("bpf: allow access into map
value arrays") but seem to have never been used.
Cc: Josef Bacik <jbacik@fb.com>
Signed-off-by: Tobias Klauser <tklauser@distanz.ch>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
tc_act macro addressed a non existing field, and was not used in the
kernel source.
Signed-off-by: Yotam Gigi <yotamg@mellanox.com>
Reviewed-by: Jiri Pirko <jiri@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
David Lebrun says:
====================
net: add support for IPv6 Segment Routing
v5:
- Check SRH validity when adding a new route with lwtunnels and
when setting an IPV6_RTHDR socket option.
- Check that hdr->segments_left is not out of bounds when processing
an SR-enabled packet.
- Add __ro_after_init attribute to seg6_genl_policy structure.
- Add CONFIG_IPV6_SEG6_INLINE option to enable or disable
direct header insertion.
v4:
- Change @cleanup in ipv6_srh_rcv() from int to bool
- Move checksum helper functions into header file
- Add common definition for SR TLVs
- Add comments for HMAC computation algorithm
- Use rhashtable to store HMAC infos instead of linked list
- Remove packed attribute for struct sr6_tlv_hmac
- Use dst cache only if CONFIG_DST_CACHE is enabled
v3:
- Fix compilation for CONFIG_IPV6={n,m}
v2:
- Remove packed attribute from sr6 struct and replaced unaligned
16-bit flags with two 8-bit flags.
- SR code now included by default. Option CONFIG_IPV6_SEG6_HMAC
exists for HMAC support (which requires crypto dependencies).
- Replace "hidden" calls to mutex_{un,}lock to direct calls.
- Fix reverse xmas tree coding style.
- Fix cast-from-void*'s.
- Update skb->csum to account for SR modifications.
- Add dst_cache in seg6_output.
Segment Routing (SR) is a source routing paradigm, architecturally
defined in draft-ietf-spring-segment-routing-09 [1]. The IPv6 flavor of
SR is defined in draft-ietf-6man-segment-routing-header-02 [2].
The main idea is that an SR-enabled packet contains a list of segments,
which represent mandatory waypoints. Each waypoint is called a segment
endpoint. The SR-enabled packet is routed normally (e.g. shortest path)
between the segment endpoints. A node that inserts an SRH into a packet
is called an ingress node, and a node that is the last segment endpoint
is called an egress node.
From an IPv6 viewpoint, an SR-enabled packet contains an IPv6 extension
header, which is a Routing Header type 4, defined as follows:
struct ipv6_sr_hdr {
__u8 nexthdr;
__u8 hdrlen;
__u8 type;
__u8 segments_left;
__u8 first_segment;
__u8 flag_1;
__u8 flag_2;
__u8 reserved;
struct in6_addr segments[0];
};
The first 4 bytes of the SRH is consistent with the Routing Header
definition in RFC 2460. The type is set to `4' (SRH).
Each segment is encoded as an IPv6 address. The segments are encoded in
reverse order: segments[0] is the last segment of the path, and
segments[first_segment] is the first segment of the path.
segments[segments_left] points to the currently active segment and
segments_left is decremented at each segment endpoint.
There exist two ways for a packet to receive an SRH, we call them
encap mode and inline mode. In the encap mode, the packet is encapsulated
in an outer IPv6 header that contains the SRH. The inner (original) packet
is not modified. A virtual tunnel is thus created between the ingress node
(the node that encapsulates) and the egress node (the last segment of the path).
Once an encapsulated SR packet reaches the egress node, the node decapsulates
the packet and performs a routing decision on the inner packet. This kind of
SRH insertion is intended to use for routers that encapsulates in-transit
packet.
The second SRH insertion method, the inline mode, acts by directly inserting
the SRH right after the IPv6 header of the original packet. For this method,
if a particular flag (SR6_FLAG_CLEANUP) is set, then the penultimate segment
endpoint must strip the SRH from the packet before forwarding it to the last
segment endpoint. This insertion method is intended to use for endhosts,
however it is also used for in-transit packets by some industry actors.
Note that directly inserting extension headers may break several mechanisms
such as Path MTU Discovery, IPSec AH, etc. For this reason, this insertion
method is only available if CONFIG_IPV6_SEG6_INLINE is enabled.
Finally, the SRH may contain TLVs after the segments list. Several types of
TLVs are defined, but we currently consider only the HMAC TLV. This TLV is
an answer to the deprecation of the RH0 and enables to ensure the authenticity
and integrity of the SRH. The HMAC text contains the flags, the first_segment
index, the full list of segments, and the source address of the packet. While
SR is intended to use mostly within a single administrative domain, the HMAC
TLV allows to verify SR packets coming from an untrusted source.
This patches series implements support for the IPv6 flavor of SR and is
logically divided into the following components:
(1) Data plane support (patch 01). This patch adds a function
in net/ipv6/exthdrs.c to handle the Routing Header type 4.
It enables the kernel to act as a segment endpoint, by supporting
the following operations: decrementation of the segments_left field,
cleanup flag support (removal of the SRH if we are the penultimate
segment endpoint) and decapsulation of the inner packet as an egress
node.
(2) Control plane support (patches 02..03 and 07..09). These patches enables
to insert SRH on locally emitted and/or forwarded packets, both with
encap mode and with inline mode. The SRH insertion is controlled through
the lightweight tunnels mechanism. Furthermore, patch 08 enables the
applications to insert an SRH on a per-socket basis, through the
setsockopt() system call. The mechanism to specify a per-socket
Routing Header was already defined for RH0 and no special modification
was performed on this side. However, the code to actually push the RH
onto the packets had to be adapted for the SRH specifications.
(3) HMAC support (patches 04..06). These patches adds the support of the
HMAC TLV verification for the dataplane part, and generation for
the control plane part. Two hashing algorithms are supported
(SHA-1 as legacy and SHA-256 as required by the IETF draft), but
additional algorithms can be easily supported by simply adding an
entry into an array.
[1] https://tools.ietf.org/html/draft-ietf-spring-segment-routing-09
[2] https://tools.ietf.org/html/draft-ietf-6man-segment-routing-header-02
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch adds documentation for some SR-related per-interface
sysctls.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch adds support for per-socket SRH injection with the setsockopt
system call through the IPPROTO_IPV6, IPV6_RTHDR options.
The SRH is pushed through the ipv6_push_nfrag_opts function.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch prepares for insertion of SRH through setsockopt().
The new source address argument is used when an HMAC field is
present in the SRH, which must be filled. The HMAC signature
process requires the source address as input text.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch enables the verification of the HMAC signature for transiting
SR-enabled packets, and its insertion on encapsulated/injected SRH.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch provides an implementation of the genetlink commands
to associate a given HMAC key identifier with an hashing algorithm
and a secret.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch adds the necessary functions to compute and check the HMAC signature
of an SR-enabled packet. Two HMAC algorithms are supported: hmac(sha1) and
hmac(sha256).
In order to avoid dynamic memory allocation for each HMAC computation,
a per-cpu ring buffer is allocated for this purpose.
A new per-interface sysctl called seg6_require_hmac is added, allowing a
user-defined policy for processing HMAC-signed SR-enabled packets.
A value of -1 means that the HMAC field will always be ignored.
A value of 0 means that if an HMAC field is present, its validity will
be enforced (the packet is dropped is the signature is incorrect).
Finally, a value of 1 means that any SR-enabled packet that does not
contain an HMAC signature or whose signature is incorrect will be dropped.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch creates a new type of interfaceless lightweight tunnel (SEG6),
enabling the encapsulation and injection of SRH within locally emitted
packets and forwarded packets.
>From a configuration viewpoint, a seg6 tunnel would be configured as follows:
ip -6 ro ad fc00::1/128 encap seg6 mode encap segs fc42::1,fc42::2,fc42::3 dev eth0
Any packet whose destination address is fc00::1 would thus be encapsulated
within an outer IPv6 header containing the SRH with three segments, and would
actually be routed to the first segment of the list. If `mode inline' was
specified instead of `mode encap', then the SRH would be directly inserted
after the IPv6 header without outer encapsulation.
The inline mode is only available if CONFIG_IPV6_SEG6_INLINE is enabled. This
feature was made configurable because direct header insertion may break
several mechanisms such as PMTUD or IPSec AH.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch adds the necessary hooks and structures to provide support
for SR-IPv6 control plane, essentially the Generic Netlink commands
that will be used for userspace control over the Segment Routing
kernel structures.
The genetlink commands provide control over two different structures:
tunnel source and HMAC data. The tunnel source is the source address
that will be used by default when encapsulating packets into an
outer IPv6 header + SRH. If the tunnel source is set to :: then an
address of the outgoing interface will be selected as the source.
The HMAC commands currently just return ENOTSUPP and will be implemented
in a future patch.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
Implement minimal support for processing of SR-enabled packets
as described in
https://tools.ietf.org/html/draft-ietf-6man-segment-routing-header-02.
This patch implements the following operations:
- Intermediate segment endpoint: incrementation of active segment and rerouting.
- Egress for SR-encapsulated packets: decapsulation of outer IPv6 header + SRH
and routing of inner packet.
- Cleanup flag support for SR-inlined packets: removal of SRH if we are the
penultimate segment endpoint.
A per-interface sysctl seg6_enabled is provided, to accept/deny SR-enabled
packets. Default is deny.
This patch does not provide support for HMAC-signed packets.
Signed-off-by: David Lebrun <david.lebrun@uclouvain.be>
Signed-off-by: David S. Miller <davem@davemloft.net>
Pablo Neira Ayuso says:
====================
Netfilter fixes for net
The following patchset contains a larger than usual batch of Netfilter
fixes for your net tree. This series contains a mixture of old bugs and
recently introduced bugs, they are:
1) Fix a crash when using nft_dynset with nft_set_rbtree, which doesn't
support the set element updates from the packet path. From Liping
Zhang.
2) Fix leak when nft_expr_clone() fails, from Liping Zhang.
3) Fix a race when inserting new elements to the set hash from the
packet path, also from Liping.
4) Handle segmented TCP SIP packets properly, basically avoid that the
INVITE in the allow header create bogus expectations by performing
stricter SIP message parsing, from Ulrich Weber.
5) nft_parse_u32_check() should return signed integer for errors, from
John Linville.
6) Fix wrong allocation instead of connlabels, allocate 16 instead of
32 bytes, from Florian Westphal.
7) Fix compilation breakage when building the ip_vs_sync code with
CONFIG_OPTIMIZE_INLINING on x86, from Arnd Bergmann.
8) Destroy the new set if the transaction object cannot be allocated,
also from Liping Zhang.
9) Use device to route duplicated packets via nft_dup only when set by
the user, otherwise packets may not follow the right route, again
from Liping.
10) Fix wrong maximum genetlink attribute definition in IPVS, from
WANG Cong.
11) Ignore untracked conntrack objects from xt_connmark, from Florian
Westphal.
12) Allow to use conntrack helpers that are registered NFPROTO_UNSPEC
via CT target, otherwise we cannot use the h.245 helper, from
Florian.
13) Revisit garbage collection heuristic in the new workqueue-based
timer approach for conntrack to evict objects earlier, again from
Florian.
14) Fix crash in nf_tables when inserting an element into a verdict map,
from Liping Zhang.
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
The newly introduced mii_ethtool_get_link_ksettings function sets
lp_advertising to an uninitialized value when BMCR_ANENABLE is not
set:
drivers/net/mii.c: In function 'mii_ethtool_get_link_ksettings':
drivers/net/mii.c:224:2: error: 'lp_advertising' may be used uninitialized in this function [-Werror=maybe-uninitialized]
As documented in include/uapi/linux/ethtool.h, the value is
expected to be zero when we don't know it, so let's initialize
it to that.
Fixes: bc8ee596af ("net: mii: add generic function to support ksetting support")
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
For single items being collected this should be preferred as being more
typesafe (as the compiler can check format string and to-be-written-to
variable match) and more efficient (requiring one less parameter to be
passed).
Signed-off-by: Jan Beulich <jbeulich@suse.com>
Reviewed-by: Paul Durrant <paul.durrant@citrix.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
There is some difference between force_igmp_version and force_mld_version.
Add document to make users aware of this.
Signed-off-by: Hangbin Liu <liuhangbin@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
To avoid having dangling function pointers left behind, reset calcit in
rtnl_unregister(), too.
This is no issue so far, as only the rtnl core registers a netlink
handler with a calcit hook which won't be unregistered, but may become
one if new code makes use of the calcit hook.
Fixes: c7ac8679be ("rtnetlink: Compute and store minimum ifinfo...")
Cc: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Cc: Greg Rose <gregory.v.rose@intel.com>
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Don't pass a size larger than iov_len to kernel_sendmsg().
Otherwise it will cause a NULL pointer deref when kernel_sendmsg()
returns with rv < size.
DRBD as external module has been around in the kernel 2.4 days already.
We used to be compatible to 2.4 and very early 2.6 kernels,
we used to use
rv = sock_sendmsg(sock, &msg, iov.iov_len);
then later changed to
rv = kernel_sendmsg(sock, &msg, &iov, 1, size);
when we should have used
rv = kernel_sendmsg(sock, &msg, &iov, 1, iov.iov_len);
tcp_sendmsg() used to totally ignore the size parameter.
57be5bd ip: convert tcp_sendmsg() to iov_iter primitives
changes that, and exposes our long standing error.
Even with this error exposed, to trigger the bug, we would need to have
an environment (config or otherwise) causing us to not use sendpage()
for larger transfers, a failing connection, and have it fail "just at the
right time". Apparently that was unlikely enough for most, so this went
unnoticed for years.
Still, it is known to trigger at least some of these,
and suspected for the others:
[0] http://lists.linbit.com/pipermail/drbd-user/2016-July/023112.html
[1] http://lists.linbit.com/pipermail/drbd-dev/2016-March/003362.html
[2] https://forums.grsecurity.net/viewtopic.php?f=3&t=4546
[3] https://ubuntuforums.org/showthread.php?t=2336150
[4] http://e2.howsolveproblem.com/i/1175162/
This should go into 4.9,
and into all stable branches since and including v4.0,
which is the first to contain the exposing change.
It is correct for all stable branches older than that as well
(which contain the DRBD driver; which is 2.6.33 and up).
It requires a small "conflict" resolution for v4.4 and earlier, with v4.5
we dropped the comment block immediately preceding the kernel_sendmsg().
Fixes: b411b3637f ("The DRBD driver")
Cc: <stable@vger.kernel.org> # 2.6.33.x-
Cc: viro@zeniv.linux.org.uk
Cc: christoph.lechleitner@iteg.at
Cc: wolfgang.glas@iteg.at
Reported-by: Christoph Lechleitner <christoph.lechleitner@iteg.at>
Tested-by: Christoph Lechleitner <christoph.lechleitner@iteg.at>
Signed-off-by: Richard Weinberger <richard@nod.at>
[changed oneliner to be "obvious" without context; more verbose message]
Signed-off-by: Lars Ellenberg <lars.ellenberg@linbit.com>
Signed-off-by: Jens Axboe <axboe@fb.com>
A bugfix introduced a harmless warning in v4.9-rc4:
drivers/net/vxlan.c: In function 'vxlan_group_used':
drivers/net/vxlan.c:947:21: error: unused variable 'sock6' [-Werror=unused-variable]
This hides the variable inside of the same #ifdef that is
around its user. The extraneous initialization is removed
at the same time, it was accidentally introduced in the
same commit.
Fixes: c6fcc4fc5f ("vxlan: avoid using stale vxlan socket.")
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Jiri Benc <jbenc@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
recv_seq, send_seq and lns_mode mode are all defined as
unsigned int foo:1;
Signed-off-by: Asbjoern Sloth Toennesen <asbjorn@asbjorn.st>
Signed-off-by: David S. Miller <davem@davemloft.net>
{kind=link}
{kind=link}