Pull namespace updates from Eric Biederman:
"This set of changes is a number of smaller things that have been
overlooked in other development cycles focused on more fundamental
change. The devpts changes are small things that were a distraction
until we managed to kill off DEVPTS_MULTPLE_INSTANCES. There is an
trivial regression fix to autofs for the unprivileged mount changes
that went in last cycle. A pair of ioctls has been added by Andrey
Vagin making it is possible to discover the relationships between
namespaces when referring to them through file descriptors.
The big user visible change is starting to add simple resource limits
to catch programs that misbehave. With namespaces in general and user
namespaces in particular allowing users to use more kinds of
resources, it has become important to have something to limit errant
programs. Because the purpose of these limits is to catch errant
programs the code needs to be inexpensive to use as it always on, and
the default limits need to be high enough that well behaved programs
on well behaved systems don't encounter them.
To this end, after some review I have implemented per user per user
namespace limits, and use them to limit the number of namespaces. The
limits being per user mean that one user can not exhause the limits of
another user. The limits being per user namespace allow contexts where
the limit is 0 and security conscious folks can remove from their
threat anlysis the code used to manage namespaces (as they have
historically done as it root only). At the same time the limits being
per user namespace allow other parts of the system to use namespaces.
Namespaces are increasingly being used in application sand boxing
scenarios so an all or nothing disable for the entire system for the
security conscious folks makes increasing use of these sandboxes
impossible.
There is also added a limit on the maximum number of mounts present in
a single mount namespace. It is nontrivial to guess what a reasonable
system wide limit on the number of mount structure in the kernel would
be, especially as it various based on how a system is using
containers. A limit on the number of mounts in a mount namespace
however is much easier to understand and set. In most cases in
practice only about 1000 mounts are used. Given that some autofs
scenarious have the potential to be 30,000 to 50,000 mounts I have set
the default limit for the number of mounts at 100,000 which is well
above every known set of users but low enough that the mount hash
tables don't degrade unreaonsably.
These limits are a start. I expect this estabilishes a pattern that
other limits for resources that namespaces use will follow. There has
been interest in making inotify event limits per user per user
namespace as well as interest expressed in making details about what
is going on in the kernel more visible"
* 'for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/ebiederm/user-namespace: (28 commits)
autofs: Fix automounts by using current_real_cred()->uid
mnt: Add a per mount namespace limit on the number of mounts
netns: move {inc,dec}_net_namespaces into #ifdef
nsfs: Simplify __ns_get_path
tools/testing: add a test to check nsfs ioctl-s
nsfs: add ioctl to get a parent namespace
nsfs: add ioctl to get an owning user namespace for ns file descriptor
kernel: add a helper to get an owning user namespace for a namespace
devpts: Change the owner of /dev/pts/ptmx to the mounter of /dev/pts
devpts: Remove sync_filesystems
devpts: Make devpts_kill_sb safe if fsi is NULL
devpts: Simplify devpts_mount by using mount_nodev
devpts: Move the creation of /dev/pts/ptmx into fill_super
devpts: Move parse_mount_options into fill_super
userns: When the per user per user namespace limit is reached return ENOSPC
userns; Document per user per user namespace limits.
mntns: Add a limit on the number of mount namespaces.
netns: Add a limit on the number of net namespaces
cgroupns: Add a limit on the number of cgroup namespaces
ipcns: Add a limit on the number of ipc namespaces
...
Pull networking updates from David Miller:
1) BBR TCP congestion control, from Neal Cardwell, Yuchung Cheng and
co. at Google. https://lwn.net/Articles/701165/
2) Do TCP Small Queues for retransmits, from Eric Dumazet.
3) Support collect_md mode for all IPV4 and IPV6 tunnels, from Alexei
Starovoitov.
4) Allow cls_flower to classify packets in ip tunnels, from Amir Vadai.
5) Support DSA tagging in older mv88e6xxx switches, from Andrew Lunn.
6) Support GMAC protocol in iwlwifi mwm, from Ayala Beker.
7) Support ndo_poll_controller in mlx5, from Calvin Owens.
8) Move VRF processing to an output hook and allow l3mdev to be
loopback, from David Ahern.
9) Support SOCK_DESTROY for UDP sockets. Also from David Ahern.
10) Congestion control in RXRPC, from David Howells.
11) Support geneve RX offload in ixgbe, from Emil Tantilov.
12) When hitting pressure for new incoming TCP data SKBs, perform a
partial rathern than a full purge of the OFO queue (which could be
huge). From Eric Dumazet.
13) Convert XFRM state and policy lookups to RCU, from Florian Westphal.
14) Support RX network flow classification to igb, from Gangfeng Huang.
15) Hardware offloading of eBPF in nfp driver, from Jakub Kicinski.
16) New skbmod packet action, from Jamal Hadi Salim.
17) Remove some inefficiencies in snmp proc output, from Jia He.
18) Add FIB notifications to properly propagate route changes to
hardware which is doing forwarding offloading. From Jiri Pirko.
19) New dsa driver for qca8xxx chips, from John Crispin.
20) Implement RFC7559 ipv6 router solicitation backoff, from Maciej
Żenczykowski.
21) Add L3 mode to ipvlan, from Mahesh Bandewar.
22) Support 802.1ad in mlx4, from Moshe Shemesh.
23) Support hardware LRO in mediatek driver, from Nelson Chang.
24) Add TC offloading to mlx5, from Or Gerlitz.
25) Convert various drivers to ethtool ksettings interfaces, from
Philippe Reynes.
26) TX max rate limiting for cxgb4, from Rahul Lakkireddy.
27) NAPI support for ath10k, from Rajkumar Manoharan.
28) Support XDP in mlx5, from Rana Shahout and Saeed Mahameed.
29) UDP replicast support in TIPC, from Richard Alpe.
30) Per-queue statistics for qed driver, from Sudarsana Reddy Kalluru.
31) Support BQL in thunderx driver, from Sunil Goutham.
32) TSO support in alx driver, from Tobias Regnery.
33) Add stream parser engine and use it in kcm.
34) Support async DHCP replies in ipconfig module, from Uwe
Kleine-König.
35) DSA port fast aging for mv88e6xxx driver, from Vivien Didelot.
* git://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next: (1715 commits)
mlxsw: switchx2: Fix misuse of hard_header_len
mlxsw: spectrum: Fix misuse of hard_header_len
net/faraday: Stop NCSI device on shutdown
net/ncsi: Introduce ncsi_stop_dev()
net/ncsi: Rework the channel monitoring
net/ncsi: Allow to extend NCSI request properties
net/ncsi: Rework request index allocation
net/ncsi: Don't probe on the reserved channel ID (0x1f)
net/ncsi: Introduce NCSI_RESERVED_CHANNEL
net/ncsi: Avoid unused-value build warning from ia64-linux-gcc
net: Add netdev all_adj_list refcnt propagation to fix panic
net: phy: Add Edge-rate driver for Microsemi PHYs.
vmxnet3: Wake queue from reset work
i40e: avoid NULL pointer dereference and recursive errors on early PCI error
qed: Add RoCE ll2 & GSI support
qed: Add support for memory registeration verbs
qed: Add support for QP verbs
qed: PD,PKEY and CQ verb support
qed: Add support for RoCE hw init
qede: Add qedr framework
...
Pull audit updates from Paul Moore:
"Another relatively small pull request for v4.9 with just two patches.
The patch from Richard updates the list of features we support and
report back to userspace; this should have been sent earlier with the
rest of the v4.8 patches but it got lost in my inbox.
The second patch fixes a problem reported by our Android friends where
we weren't very consistent in recording PIDs"
* 'stable-4.9' of git://git.infradead.org/users/pcmoore/audit:
audit: add exclude filter extension to feature bitmap
audit: consistently record PIDs with task_tgid_nr()
This reverts commit 4fa5cd5245.
The original change widens a preempt-off section, to avoid a seemingly unsafe
smp_processor_id() use.
During review I overlooked two facts:
- The code to calls a non-trivial function callback:
ht->park(td->cpu);
... which might (and does occasionally) sleep, triggering the warning.
- More importantly, as pointed out by Peter Zijlstra, using
smp_processor_id() in that context is safe, if it's done from
a kernel thread that is pinned to a single CPU - which is the
case here.
So revert to the original code that enables preemption sooner.
Reported-by: kernel test robot <xiaolong.ye@intel.com>
Acked-by: Peter Zijlstra <peterz@infradead.org>
Cc: Con Kolivas <kernel@kolivas.org>
Cc: Alfred Chen <cchalpha@gmail.com>
Link: http://lkml.kernel.org/r/20160930015102.GB20189@yexl-desktop
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Pull CPU hotplug updates from Thomas Gleixner:
"Yet another batch of cpu hotplug core updates and conversions:
- Provide core infrastructure for multi instance drivers so the
drivers do not have to keep custom lists.
- Convert custom lists to the new infrastructure. The block-mq custom
list conversion comes through the block tree and makes the diffstat
tip over to more lines removed than added.
- Handle unbalanced hotplug enable/disable calls more gracefully.
- Remove the obsolete CPU_STARTING/DYING notifier support.
- Convert another batch of notifier users.
The relayfs changes which conflicted with the conversion have been
shipped to me by Andrew.
The remaining lot is targeted for 4.10 so that we finally can remove
the rest of the notifiers"
* 'smp-hotplug-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (46 commits)
cpufreq: Fix up conversion to hotplug state machine
blk/mq: Reserve hotplug states for block multiqueue
x86/apic/uv: Convert to hotplug state machine
s390/mm/pfault: Convert to hotplug state machine
mips/loongson/smp: Convert to hotplug state machine
mips/octeon/smp: Convert to hotplug state machine
fault-injection/cpu: Convert to hotplug state machine
padata: Convert to hotplug state machine
cpufreq: Convert to hotplug state machine
ACPI/processor: Convert to hotplug state machine
virtio scsi: Convert to hotplug state machine
oprofile/timer: Convert to hotplug state machine
block/softirq: Convert to hotplug state machine
lib/irq_poll: Convert to hotplug state machine
x86/microcode: Convert to hotplug state machine
sh/SH-X3 SMP: Convert to hotplug state machine
ia64/mca: Convert to hotplug state machine
ARM/OMAP/wakeupgen: Convert to hotplug state machine
ARM/shmobile: Convert to hotplug state machine
arm64/FP/SIMD: Convert to hotplug state machine
...
Pull irq updates from Thomas Gleixner:
"The irq departement proudly presents:
- A rework of the core infrastructure to optimally spread interrupt
for multiqueue devices. The first version was a bit naive and
failed to take thread siblings and other details into account.
Developed in cooperation with Christoph and Keith.
- Proper delegation of softirqs to ksoftirqd, so if ksoftirqd is
active then no further softirq processsing on interrupt return
happens. Otherwise we try to delegate and still run another batch
of network packets in the irq return path, which then tries to
delegate to ksoftirqd .....
- A proper machine parseable sysfs based alternative for
/proc/interrupts.
- ACPI support for the GICV3-ITS and ARM interrupt remapping
- Two new irq chips from the ARM SoC zoo: STM32-EXTI and MVEBU-PIC
- A new irq chip for the JCore (SuperH)
- The usual pile of small fixlets in core and irqchip drivers"
* 'irq-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (42 commits)
softirq: Let ksoftirqd do its job
genirq: Make function __irq_do_set_handler() static
ARM/dts: Add EXTI controller node to stm32f429
ARM/STM32: Select external interrupts controller
drivers/irqchip: Add STM32 external interrupts support
Documentation/dt-bindings: Document STM32 EXTI controller bindings
irqchip/mips-gic: Use for_each_set_bit to iterate over local IRQs
pci/msi: Retrieve affinity for a vector
genirq/affinity: Remove old irq spread infrastructure
genirq/msi: Switch to new irq spreading infrastructure
genirq/affinity: Provide smarter irq spreading infrastructure
genirq/msi: Add cpumask allocation to alloc_msi_entry
genirq: Expose interrupt information through sysfs
irqchip/gicv3-its: Use MADT ITS subtable to do PCI/MSI domain initialization
irqchip/gicv3-its: Factor out PCI-MSI part that might be reused for ACPI
irqchip/gicv3-its: Probe ITS in the ACPI way
irqchip/gicv3-its: Refactor ITS DT init code to prepare for ACPI
irqchip/gicv3-its: Cleanup for ITS domain initialization
PCI/MSI: Setup MSI domain on a per-device basis using IORT ACPI table
ACPI: Add new IORT functions to support MSI domain handling
...
Pull timer updates from Thomas Gleixner:
"A rather smalish set of updates for timers and timekeeping:
- Two core fixes to prevent potential undefinded behaviour about
which gcc is complaining rightfully.
- A fix to prevent stopping the tick on an (soon) offline CPU so it
can complete the shutdown procedure.
- Wait for clocks to stabilize before making decisions, so a not yet
validated clock is not rejected.
- The usual pile of fixes to the various clocksource drivers.
- Core code typo and include fixlets"
* 'timers-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
timekeeping: Include the correct header for errno definitions
clocksource/drivers/ti-32k: Prevent ftrace recursion
clocksource/mips-gic-timer: Stop checking cpu_has_counter
clocksource/mips-gic-timer: Print an error if IRQ setup fails
tick/nohz: Prevent stopping the tick on an offline CPU
clocksource/drivers/oxnas: Add OX820 compatible
clocksource/drivers/timer-atmel-pit: Simplify IRQ handler
clocksource/drivers/timer-atmel-pit: Remove uselesss WARN_ON_ONCE
clocksource/drivers/timer-atmel-pit: Drop at91sam926x_pit_common_init
clocksource/drivers/moxart: Replace panic by pr_err
clocksource/drivers/moxart: Replace setup_irq by request_irq
clocksource/drivers/moxart: Add Aspeed support
clocksource/drivers/moxart: Use struct to hold state
clocksource/drivers/moxart: Refactor enable/disable
time: Avoid undefined behaviour in ktime_add_safe()
time: Avoid undefined behaviour in timespec64_add_safe()
timekeeping: Prints the amounts of time spent during suspend
clocksource: Defer override invalidation unless clock is unstable
hrtimer: Spelling fixes
Pull x86 vdso updates from Ingo Molnar:
"The main changes in this cycle centered around adding support for
32-bit compatible C/R of the vDSO on 64-bit kernels, by Dmitry
Safonov"
* 'x86-vdso-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/vdso: Use CONFIG_X86_X32_ABI to enable vdso prctl
x86/vdso: Only define map_vdso_randomized() if CONFIG_X86_64
x86/vdso: Only define prctl_map_vdso() if CONFIG_CHECKPOINT_RESTORE
x86/signal: Add SA_{X32,IA32}_ABI sa_flags
x86/ptrace: Down with test_thread_flag(TIF_IA32)
x86/coredump: Use pr_reg size, rather that TIF_IA32 flag
x86/arch_prctl/vdso: Add ARCH_MAP_VDSO_*
x86/vdso: Replace calculate_addr in map_vdso() with addr
x86/vdso: Unmap vdso blob on vvar mapping failure
Pull low-level x86 updates from Ingo Molnar:
"In this cycle this topic tree has become one of those 'super topics'
that accumulated a lot of changes:
- Add CONFIG_VMAP_STACK=y support to the core kernel and enable it on
x86 - preceded by an array of changes. v4.8 saw preparatory changes
in this area already - this is the rest of the work. Includes the
thread stack caching performance optimization. (Andy Lutomirski)
- switch_to() cleanups and all around enhancements. (Brian Gerst)
- A large number of dumpstack infrastructure enhancements and an
unwinder abstraction. The secret long term plan is safe(r) live
patching plus maybe another attempt at debuginfo based unwinding -
but all these current bits are standalone enhancements in a frame
pointer based debug environment as well. (Josh Poimboeuf)
- More __ro_after_init and const annotations. (Kees Cook)
- Enable KASLR for the vmemmap memory region. (Thomas Garnier)"
[ The virtually mapped stack changes are pretty fundamental, and not
x86-specific per se, even if they are only used on x86 right now. ]
* 'x86-asm-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (70 commits)
x86/asm: Get rid of __read_cr4_safe()
thread_info: Use unsigned long for flags
x86/alternatives: Add stack frame dependency to alternative_call_2()
x86/dumpstack: Fix show_stack() task pointer regression
x86/dumpstack: Remove dump_trace() and related callbacks
x86/dumpstack: Convert show_trace_log_lvl() to use the new unwinder
oprofile/x86: Convert x86_backtrace() to use the new unwinder
x86/stacktrace: Convert save_stack_trace_*() to use the new unwinder
perf/x86: Convert perf_callchain_kernel() to use the new unwinder
x86/unwind: Add new unwind interface and implementations
x86/dumpstack: Remove NULL task pointer convention
fork: Optimize task creation by caching two thread stacks per CPU if CONFIG_VMAP_STACK=y
sched/core: Free the stack early if CONFIG_THREAD_INFO_IN_TASK
lib/syscall: Pin the task stack in collect_syscall()
x86/process: Pin the target stack in get_wchan()
x86/dumpstack: Pin the target stack when dumping it
kthread: Pin the stack via try_get_task_stack()/put_task_stack() in to_live_kthread() function
sched/core: Add try_get_task_stack() and put_task_stack()
x86/entry/64: Fix a minor comment rebase error
iommu/amd: Don't put completion-wait semaphore on stack
...
Pull perf updates from Ingo Molnar:
"The main kernel side changes were:
- uprobes enhancements (Masami Hiramatsu)
- Uncore group events enhancements (David Carrillo-Cisneros)
- x86 Intel: Add support for Skylake server uncore PMUs (Kan Liang)
- x86 Intel: LBR cleanups and enhancements, for better branch
annotation tracking (Peter Zijlstra)
- x86 Intel: Add support for PTWRITE and power event tracing
(Alexander Shishkin)
- ... various fixes, cleanups and smaller enhancements.
Lots of tooling changes - a couple of highlights:
- Support event group view with hierarchy mode in 'perf top' and
'perf report' (Namhyung Kim)
e.g.:
$ perf record -e '{cycles,instructions}' make
$ perf report --hierarchy --stdio
...
# Overhead Command / Shared Object / Symbol
# ...................... ..................................
...
25.74% 27.18%sh
19.96% 24.14%libc-2.24.so
9.55% 14.64%[.] __strcmp_sse2
1.54% 0.00%[.] __tfind
1.07% 1.13%[.] _int_malloc
0.95% 0.00%[.] __strchr_sse2
0.89% 1.39%[.] __tsearch
0.76% 0.00%[.] strlen
- Add branch stack / basic block info to 'perf annotate --stdio',
where for each branch, we add an asm comment after the instruction
with information on how often it was taken and predicted. See
example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Add support for using symbols in address filters with Intel PT and
ARM CoreSight (hardware assisted tracing facilities) (Adrian
Hunter, Mathieu Poirier)
- Add support for interacting with Coresight PMU ETMs/PTMs, that are
IP blocks to perform hardware assisted tracing on a ARM CPU core
(Mathieu Poirier)
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Allow configuring the default 'perf report -s' sort order in
~/.perfconfig, for instance, "sym,dso" may be more fitting for
kernel developers. (Arnaldo Carvalho de Melo)
- ... plus lots of other changes, refactorings, features and fixes"
* 'perf-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (149 commits)
perf tests: Add dwarf unwind test for powerpc
perf probe: Match linkage name with mangled name
perf probe: Fix to cut off incompatible chars from group name
perf probe: Skip if the function address is 0
perf probe: Ignore the error of finding inline instance
perf intel-pt: Fix decoding when there are address filters
perf intel-pt: Enable decoder to handle TIP.PGD with missing IP
perf intel-pt: Read address filter from AUXTRACE_INFO event
perf intel-pt: Record address filter in AUXTRACE_INFO event
perf intel-pt: Add a helper function for processing AUXTRACE_INFO
perf intel-pt: Fix missing error codes processing auxtrace_info
perf intel-pt: Add support for recording the max non-turbo ratio
perf intel-pt: Fix snapshot overlap detection decoder errors
perf probe: Increase debug level of SDT debug messages
perf record: Add support for using symbols in address filters
perf symbols: Add dso__last_symbol()
perf record: Fix error paths
perf record: Rename label 'out_symbol_exit'
perf script: Fix vanished idle symbols
perf evsel: Add support for address filters
...
Pull locking updates from Ingo Molnar:
"The main changes in this cycle were:
- rwsem micro-optimizations (Davidlohr Bueso)
- Improve the implementation and optimize the performance of
percpu-rwsems. (Peter Zijlstra.)
- Convert all lglock users to better facilities such as percpu-rwsems
or percpu-spinlocks and remove lglocks. (Peter Zijlstra)
- Remove the ticket (spin)lock implementation. (Peter Zijlstra)
- Korean translation of memory-barriers.txt and related fixes to the
English document. (SeongJae Park)
- misc fixes and cleanups"
* 'locking-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (24 commits)
x86/cmpxchg, locking/atomics: Remove superfluous definitions
x86, locking/spinlocks: Remove ticket (spin)lock implementation
locking/lglock: Remove lglock implementation
stop_machine: Remove stop_cpus_lock and lg_double_lock/unlock()
fs/locks: Use percpu_down_read_preempt_disable()
locking/percpu-rwsem: Add down_read_preempt_disable()
fs/locks: Replace lg_local with a per-cpu spinlock
fs/locks: Replace lg_global with a percpu-rwsem
locking/percpu-rwsem: Add DEFINE_STATIC_PERCPU_RWSEMand percpu_rwsem_assert_held()
locking/pv-qspinlock: Use cmpxchg_release() in __pv_queued_spin_unlock()
locking/rwsem, x86: Drop a bogus cc clobber
futex: Add some more function commentry
locking/hung_task: Show all locks
locking/rwsem: Scan the wait_list for readers only once
locking/rwsem: Remove a few useless comments
locking/rwsem: Return void in __rwsem_mark_wake()
locking, rcu, cgroup: Avoid synchronize_sched() in __cgroup_procs_write()
locking/Documentation: Add Korean translation
locking/Documentation: Fix a typo of example result
locking/Documentation: Fix wrong section reference
...
Pull core SMP updates from Ingo Molnar:
"Two main change is generic vCPU pinning and physical CPU SMP-call
support, for Xen to be able to perform certain calls on specific
physical CPUs - by Juergen Gross"
* 'core-smp-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
smp: Allocate smp_call_on_cpu() workqueue on stack too
hwmon: Use smp_call_on_cpu() for dell-smm i8k
dcdbas: Make use of smp_call_on_cpu()
xen: Add xen_pin_vcpu() to support calling functions on a dedicated pCPU
smp: Add function to execute a function synchronously on a CPU
virt, sched: Add generic vCPU pinning support
xen: Sync xen header
Pull RCU updates from Ingo Molnar:
"The main changes in this cycle were:
- Expedited grace-period changes, most notably avoiding having user
threads drive expedited grace periods, using a workqueue instead.
- Miscellaneous fixes, including a performance fix for lists that was
sent with the lists modifications.
- CPU hotplug updates, most notably providing exact CPU-online
tracking for RCU. This will in turn allow removal of the checks
supporting RCU's prior heuristic that was based on the assumption
that CPUs would take no longer than one jiffy to come online.
- Torture-test updates.
- Documentation updates"
* 'core-rcu-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (22 commits)
list: Expand list_first_entry_or_null()
torture: TOROUT_STRING(): Insert a space between flag and message
rcuperf: Consistently insert space between flag and message
rcutorture: Print out barrier error as document says
torture: Add task state to writer-task stall printk()s
torture: Convert torture_shutdown() to hrtimer
rcutorture: Convert to hotplug state machine
cpu/hotplug: Get rid of CPU_STARTING reference
rcu: Provide exact CPU-online tracking for RCU
rcu: Avoid redundant quiescent-state chasing
rcu: Don't use modular infrastructure in non-modular code
sched: Make wake_up_nohz_cpu() handle CPUs going offline
rcu: Use rcu_gp_kthread_wake() to wake up grace period kthreads
rcu: Use RCU's online-CPU state for expedited IPI retry
rcu: Exclude RCU-offline CPUs from expedited grace periods
rcu: Make expedited RCU CPU stall warnings respond to controls
rcu: Stop disabling expedited RCU CPU stall warnings
rcu: Drive expedited grace periods from workqueue
rcu: Consolidate expedited grace period machinery
documentation: Record reason for rcu_head two-byte alignment
...
- Add a mechanism for passing hints from the scheduler to cpufreq governors
via their utilization update callbacks and use it to introduce "IOwait
boosting" into the schedutil governor and intel_pstate that will make them
boost performance if the enqueued task was previously waiting on I/O
(Rafael Wysocki).
- Fix a schedutil governor problem that causes it to overestimate utilization
if SMT is in use (Steve Muckle).
- Update defconfigs trying to use the schedutil governor as a module which is
not possible any more (Javier Martinez Canillas).
- Update the intel_pstate's pstate_sample tracepoint to take "IOwait boosting"
into account (Srinivas Pandruvada).
- Fix a problem in the cpufreq core causing it to mishandle the initialization
of CPUs registered after the cpufreq driver (Viresh Kumar, Rafael Wysocki).
- Make the cpufreq-dt driver support per-policy governor tunables, clean it
up and update its Kconfig description (Viresh Kumar).
- Add support for more ARM platforms to the cpufreq-dt driver (Chanwoo Choi,
Dave Gerlach, Geert Uytterhoeven).
- Make the cpufreq CPPC driver report frequencies in KHz to avoid user space
compatiblility issues (Al Stone, Hoan Tran).
- Clean up a few cpufreq drivers (st, kirkwood, SCPI) a bit (Colin Ian King,
Markus Elfring).
- Constify some local structures in the intel_pstate driver (Julia Lawall).
- Add a Documentation/cpu-freq/ entry to MAINTAINERS (Jean Delvare).
- Add support for PM domain removal to the generic power domains (genpd)
framework, add new DT helper functions to it and make it always enable
debugfs support if available (Jon Hunter, Tomeu Vizoso).
- Clean up the generic power domains (genpd) framework and make it avoid
measuring power-on and power-off latencies during system-wide PM transitions
(Ulf Hansson).
- Add support for the RockChip DFI controller and the rk3399 DMC to the
devfreq framework (Lin Huang, Axel Lin, Arnd Bergmann).
- Add COMPILE_TEST to the devfreq framework (Krzysztof Kozlowski, Stephen
Rothwell).
- Fix a minor issue in the exynos-ppmu devfreq driver and fix up devfreq
Kconfig indentation style (Wei Yongjun, Jisheng Zhang).
- Fix the system suspend interface to make suspend-to-idle work if platform
suspend operations have not been registered (Sudeep Holla).
- Make it possible to use hibernation with PAGE_POISONING_ZERO enabled
(Anisse Astier).
- Increas the default timeout of the system suspend/resume watchdog and make it
depend on EXPERT (Chen Yu).
- Make the operating performance points (OPP) framework avoid using OPPs that
aren't supported by the platform and fix a build warning in it (Dave Gerlach,
Arnd Bergmann).
- Fix the ARM cpuidle driver's return value (Christophe Jaillet).
- Make the SmartReflex AVS (Adaptive Voltage Scaling) driver use more common
logging style (Joe Perches).
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2.0.22 (GNU/Linux)
iQIcBAABCAAGBQJX8Y32AAoJEILEb/54YlRx8e0P/27zu8Lb6Aks1S2Zx9GEW0qr
DvrO4kklCHqi3DgHlyFOYetf9cxMrUluojVJofnoSDvgAayWyg7VAd4gtOrMGCXG
pJVJM73itcOUK+DsAVvoWJY3hk15nX77n2aiXPN2GqaMqennlQusdfzTmjCasqpm
M84j+JwFYlJcfyMCcF5kGWqS7QBjzxhA0CjytUX1i3pL3NqRALZUEpaHwBD1W+4r
tcF/jYTy3RsghCbuC6HoPxEF9NMOFGxeAXogmu6NvGu8gy0GqtywRSRrs5wA1a0z
ZDAJ8krrFbzuFPMdjNIE8wtTeziofS5i9piQx3JlIMH3HpNGN86BRXVfzuHzJj11
6ZMUI/FJy+fYukIXOEeVLtsLHUnMcMux8Jq1UF6N0InahaR9nbsjmGOmXh72+Scx
7VJ+29l0oVwX6wkw/DjPP3rb1Swd1i3yY0/3uRoJ174mYTjhRGbrbDkIjPiDeuM5
2Cx7QunscOjFmaNtPyr8niQ+7YhMEpn8VIbGNaX5ABz0fGftfi8nDHqliSNa391Z
nK6YoKD0O6R0JHE6GavvJTcuMS9qE+HHHOwymWKxEdE9KYk0JUqen3gj1sSTaAZT
BIPBsn6XlorqNy3dnqtWTHV7Nf0al9huolWvrL90s6g4Bh2BzTzDVydSgNWTMDUi
G64nP0q1sJTqdoe30uvk
=NYkv
-----END PGP SIGNATURE-----
Merge tag 'pm-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm
Pull power management updates from Rafael Wysocki:
"Traditionally, cpufreq is the area with the greatest number of
changes, but there are fewer of them than last time. There also is
some activity in the generic power domains and the devfreq frameworks,
a couple of system suspend and hibernation fixes and some assorted
changes in other places.
One new feature is the cpufreq change to allow the scheduler to pass
hints to the governors' utilization update callbacks and some code
rework based on that. Another one is the support for domain removal in
the generic power domains framework. Also it is now possible to use
hibernation with PAGE_POISONING_ZERO enabled and devfreq supports the
RockChip DFI controller and the rk3399 DMC.
The rest of the changes is mostly fixes and cleanups in a number of
places.
Specifics:
- Add a mechanism for passing hints from the scheduler to cpufreq
governors via their utilization update callbacks and use it to
introduce "IOwait boosting" into the schedutil governor and
intel_pstate that will make them boost performance if the enqueued
task was previously waiting on I/O (Rafael Wysocki).
- Fix a schedutil governor problem that causes it to overestimate
utilization if SMT is in use (Steve Muckle).
- Update defconfigs trying to use the schedutil governor as a module
which is not possible any more (Javier Martinez Canillas).
- Update the intel_pstate's pstate_sample tracepoint to take "IOwait
boosting" into account (Srinivas Pandruvada).
- Fix a problem in the cpufreq core causing it to mishandle the
initialization of CPUs registered after the cpufreq driver (Viresh
Kumar, Rafael Wysocki).
- Make the cpufreq-dt driver support per-policy governor tunables,
clean it up and update its Kconfig description (Viresh Kumar).
- Add support for more ARM platforms to the cpufreq-dt driver
(Chanwoo Choi, Dave Gerlach, Geert Uytterhoeven).
- Make the cpufreq CPPC driver report frequencies in KHz to avoid
user space compatiblility issues (Al Stone, Hoan Tran).
- Clean up a few cpufreq drivers (st, kirkwood, SCPI) a bit (Colin
Ian King, Markus Elfring).
- Constify some local structures in the intel_pstate driver (Julia
Lawall).
- Add a Documentation/cpu-freq/ entry to MAINTAINERS (Jean Delvare).
- Add support for PM domain removal to the generic power domains
(genpd) framework, add new DT helper functions to it and make it
always enable debugfs support if available (Jon Hunter, Tomeu
Vizoso).
- Clean up the generic power domains (genpd) framework and make it
avoid measuring power-on and power-off latencies during system-wide
PM transitions (Ulf Hansson).
- Add support for the RockChip DFI controller and the rk3399 DMC to
the devfreq framework (Lin Huang, Axel Lin, Arnd Bergmann).
- Add COMPILE_TEST to the devfreq framework (Krzysztof Kozlowski,
Stephen Rothwell).
- Fix a minor issue in the exynos-ppmu devfreq driver and fix up
devfreq Kconfig indentation style (Wei Yongjun, Jisheng Zhang).
- Fix the system suspend interface to make suspend-to-idle work if
platform suspend operations have not been registered (Sudeep
Holla).
- Make it possible to use hibernation with PAGE_POISONING_ZERO
enabled (Anisse Astier).
- Increas the default timeout of the system suspend/resume watchdog
and make it depend on EXPERT (Chen Yu).
- Make the operating performance points (OPP) framework avoid using
OPPs that aren't supported by the platform and fix a build warning
in it (Dave Gerlach, Arnd Bergmann).
- Fix the ARM cpuidle driver's return value (Christophe Jaillet).
- Make the SmartReflex AVS (Adaptive Voltage Scaling) driver use more
common logging style (Joe Perches)"
* tag 'pm-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm: (58 commits)
PM / OPP: Don't support OPP if it provides supported-hw but platform does not
cpufreq: st: add missing \n to end of dev_err message
cpufreq: kirkwood: add missing \n to end of dev_err messages
PM / Domains: Rename pm_genpd_sync_poweron|poweroff()
PM / Domains: Don't measure latency of ->power_on|off() during system PM
PM / Domains: Remove redundant system PM callbacks
PM / Domains: Simplify detaching a device from its genpd
PM / devfreq: rk3399_dmc: Remove explictly regulator_put call in .remove
PM / devfreq: rockchip: add PM_DEVFREQ_EVENT dependency
PM / OPP: avoid maybe-uninitialized warning
PM / Domains: Allow holes in genpd_data.domains array
cpufreq: CPPC: Avoid overflow when calculating desired_perf
cpufreq: ti: Use generic platdev driver
cpufreq: intel_pstate: Add io_boost trace
partial revert of "PM / devfreq: Add COMPILE_TEST for build coverage"
cpufreq: intel_pstate: Use IOWAIT flag in Atom algorithm
cpufreq: schedutil: Add iowait boosting
cpufreq / sched: SCHED_CPUFREQ_IOWAIT flag to indicate iowait condition
PM / Domains: Add support for removing nested PM domains by provider
PM / Domains: Add support for removing PM domains
...
- Support for execute-only page permissions
- Support for hibernate and DEBUG_PAGEALLOC
- Support for heterogeneous systems with mismatches cache line sizes
- Errata workarounds (A53 843419 update and QorIQ A-008585 timer bug)
- arm64 PMU perf updates, including cpumasks for heterogeneous systems
- Set UTS_MACHINE for building rpm packages
- Yet another head.S tidy-up
- Some cleanups and refactoring, particularly in the NUMA code
- Lots of random, non-critical fixes across the board
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABCgAGBQJX7k31AAoJELescNyEwWM0XX0H/iOaWCfKlWOhvBsStGUCsLrK
XryTzQT2KjdnLKf3jwP+1ateCuBR5ROurYxoDCX5/7mD63c5KiI338Vbv61a1lE1
AAwjt1stmQVUg/j+kqnuQwB/0DYg+2C8se3D3q5Iyn7zc19cDZJEGcBHNrvLMufc
XgHrgHgl/rzBDDlHJXleknDFge/MfhU5/Q1vJMRRb4JYrpAtmIokzCO75CYMRcCT
ND2QbmppKtsyuFPGUTVbAFzJlP6dGKb3eruYta7/ct5d0pJQxav3u98D2yWGfjdM
YaYq1EmX5Pol7rWumqLtk0+mA9yCFcKLLc+PrJu20Vx0UkvOq8G8Xt70sHNvZU8=
=gdPM
-----END PGP SIGNATURE-----
Merge tag 'arm64-upstream' of git://git.kernel.org/pub/scm/linux/kernel/git/arm64/linux
Pull arm64 updates from Will Deacon:
"It's a bit all over the place this time with no "killer feature" to
speak of. Support for mismatched cache line sizes should help people
seeing whacky JIT failures on some SoCs, and the big.LITTLE perf
updates have been a long time coming, but a lot of the changes here
are cleanups.
We stray outside arch/arm64 in a few areas: the arch/arm/ arch_timer
workaround is acked by Russell, the DT/OF bits are acked by Rob, the
arch_timer clocksource changes acked by Marc, CPU hotplug by tglx and
jump_label by Peter (all CC'd).
Summary:
- Support for execute-only page permissions
- Support for hibernate and DEBUG_PAGEALLOC
- Support for heterogeneous systems with mismatches cache line sizes
- Errata workarounds (A53 843419 update and QorIQ A-008585 timer bug)
- arm64 PMU perf updates, including cpumasks for heterogeneous systems
- Set UTS_MACHINE for building rpm packages
- Yet another head.S tidy-up
- Some cleanups and refactoring, particularly in the NUMA code
- Lots of random, non-critical fixes across the board"
* tag 'arm64-upstream' of git://git.kernel.org/pub/scm/linux/kernel/git/arm64/linux: (100 commits)
arm64: tlbflush.h: add __tlbi() macro
arm64: Kconfig: remove SMP dependence for NUMA
arm64: Kconfig: select OF/ACPI_NUMA under NUMA config
arm64: fix dump_backtrace/unwind_frame with NULL tsk
arm/arm64: arch_timer: Use archdata to indicate vdso suitability
arm64: arch_timer: Work around QorIQ Erratum A-008585
arm64: arch_timer: Add device tree binding for A-008585 erratum
arm64: Correctly bounds check virt_addr_valid
arm64: migrate exception table users off module.h and onto extable.h
arm64: pmu: Hoist pmu platform device name
arm64: pmu: Probe default hw/cache counters
arm64: pmu: add fallback probe table
MAINTAINERS: Update ARM PMU PROFILING AND DEBUGGING entry
arm64: Improve kprobes test for atomic sequence
arm64/kvm: use alternative auto-nop
arm64: use alternative auto-nop
arm64: alternative: add auto-nop infrastructure
arm64: lse: convert lse alternatives NOP padding to use __nops
arm64: barriers: introduce nops and __nops macros for NOP sequences
arm64: sysreg: replace open-coded mrs_s/msr_s with {read,write}_sysreg_s
...
* pm-cpufreq: (24 commits)
cpufreq: st: add missing \n to end of dev_err message
cpufreq: kirkwood: add missing \n to end of dev_err messages
cpufreq: CPPC: Avoid overflow when calculating desired_perf
cpufreq: ti: Use generic platdev driver
cpufreq: intel_pstate: Add io_boost trace
cpufreq: intel_pstate: Use IOWAIT flag in Atom algorithm
cpufreq: schedutil: Add iowait boosting
cpufreq / sched: SCHED_CPUFREQ_IOWAIT flag to indicate iowait condition
cpufreq: CPPC: Force reporting values in KHz to fix user space interface
cpufreq: create link to policy only for registered CPUs
intel_pstate: constify local structures
cpufreq: dt: Support governor tunables per policy
cpufreq: dt: Update kconfig description
cpufreq: dt: Remove unused code
MAINTAINERS: Add Documentation/cpu-freq/
cpufreq: dt: Add support for r8a7792
cpufreq / sched: ignore SMT when determining max cpu capacity
cpufreq: Drop unnecessary check from cpufreq_policy_alloc()
ARM: multi_v7_defconfig: Don't attempt to enable schedutil governor as module
ARM: exynos_defconfig: Don't attempt to enable schedutil governor as module
...
CAI Qian <caiqian@redhat.com> pointed out that the semantics
of shared subtrees make it possible to create an exponentially
increasing number of mounts in a mount namespace.
mkdir /tmp/1 /tmp/2
mount --make-rshared /
for i in $(seq 1 20) ; do mount --bind /tmp/1 /tmp/2 ; done
Will create create 2^20 or 1048576 mounts, which is a practical problem
as some people have managed to hit this by accident.
As such CVE-2016-6213 was assigned.
Ian Kent <raven@themaw.net> described the situation for autofs users
as follows:
> The number of mounts for direct mount maps is usually not very large because of
> the way they are implemented, large direct mount maps can have performance
> problems. There can be anywhere from a few (likely case a few hundred) to less
> than 10000, plus mounts that have been triggered and not yet expired.
>
> Indirect mounts have one autofs mount at the root plus the number of mounts that
> have been triggered and not yet expired.
>
> The number of autofs indirect map entries can range from a few to the common
> case of several thousand and in rare cases up to between 30000 and 50000. I've
> not heard of people with maps larger than 50000 entries.
>
> The larger the number of map entries the greater the possibility for a large
> number of active mounts so it's not hard to expect cases of a 1000 or somewhat
> more active mounts.
So I am setting the default number of mounts allowed per mount
namespace at 100,000. This is more than enough for any use case I
know of, but small enough to quickly stop an exponential increase
in mounts. Which should be perfect to catch misconfigurations and
malfunctioning programs.
For anyone who needs a higher limit this can be changed by writing
to the new /proc/sys/fs/mount-max sysctl.
Tested-by: CAI Qian <caiqian@redhat.com>
Signed-off-by: "Eric W. Biederman" <ebiederm@xmission.com>
The code performing irqtime nsecs stats flushing to kcpustat is roughly
the same for hardirq and softirq. So lets consolidate that common code.
Signed-off-by: Frederic Weisbecker <fweisbec@gmail.com>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Wanpeng Li <wanpeng.li@hotmail.com>
Link: http://lkml.kernel.org/r/1474849761-12678-6-git-send-email-fweisbec@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The irqtime accounting currently implement its own ad hoc implementation
of u64_stats API. Lets rather consolidate it with the appropriate
library.
Signed-off-by: Frederic Weisbecker <fweisbec@gmail.com>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Wanpeng Li <wanpeng.li@hotmail.com>
Link: http://lkml.kernel.org/r/1474849761-12678-5-git-send-email-fweisbec@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The callers of the functions performing irqtime kcpustat updates have
IRQS disabled, no need to disable them again.
Signed-off-by: Frederic Weisbecker <fweisbec@gmail.com>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Wanpeng Li <wanpeng.li@hotmail.com>
Link: http://lkml.kernel.org/r/1474849761-12678-3-git-send-email-fweisbec@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
We can safely use the preempt-unsafe accessors for irqtime when we
flush its counters to kcpustat as IRQs are disabled at this time.
Signed-off-by: Frederic Weisbecker <fweisbec@gmail.com>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Wanpeng Li <wanpeng.li@hotmail.com>
Link: http://lkml.kernel.org/r/1474849761-12678-2-git-send-email-fweisbec@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
While going through enqueue/dequeue to review the movement of
set_curr_task() I noticed that the (2nd) update_min_vruntime() call in
dequeue_entity() is suspect.
It turns out, its actually wrong because it will consider
cfs_rq->curr, which could be the entry we just normalized. This mixes
different vruntime forms and leads to fail.
The purpose of the second update_min_vruntime() is to move
min_vruntime forward if the entity we just removed is the one that was
holding it back; _except_ for the DEQUEUE_SAVE case, because then we
know its a temporary removal and it will come back.
However, since we do put_prev_task() _after_ dequeue(), cfs_rq->curr
will still be set (and per the above, can be tranformed into a
different unit), so update_min_vruntime() should also consider
curr->on_rq. This also fixes another corner case where the enqueue
(which also does update_curr()->update_min_vruntime()) happens on the
rq->lock break in schedule(), between dequeue and put_prev_task.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Fixes: 1e87623178 ("sched: Fix ->min_vruntime calculation in dequeue_entity()")
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Provide SCHED_WARN_ON as wrapper for WARN_ON_ONCE() to avoid
CONFIG_SCHED_DEBUG wrappery.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Almost all scheduler functions update state with the following
pattern:
if (queued)
dequeue_task(rq, p, DEQUEUE_SAVE);
if (running)
put_prev_task(rq, p);
/* update state */
if (queued)
enqueue_task(rq, p, ENQUEUE_RESTORE);
if (running)
set_curr_task(rq, p);
set_user_nice() however misses the running part, cure this.
This was found by asserting we never enqueue 'current'.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Now that the ia64 only set_curr_task() symbol is gone, provide a
helper just like put_prev_task().
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Rename the ia64 only set_curr_task() function to free up the name.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Tony Luck <tony.luck@intel.com>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
When a task switches to fair scheduling class, the period between now
and the last update of its utilization is accounted as running time
whatever happened during this period. This incorrect accounting applies
to the task and also to the task group branch.
When changing the property of a running task like its list of allowed
CPUs or its scheduling class, we follow the sequence:
- dequeue task
- put task
- change the property
- set task as current task
- enqueue task
The end of the sequence doesn't follow the normal sequence (as per
__schedule()) which is:
- enqueue a task
- then set the task as current task.
This incorrectordering is the root cause of incorrect utilization accounting.
Update the sequence to follow the right one:
- dequeue task
- put task
- change the property
- enqueue task
- set task as current task
Signed-off-by: Vincent Guittot <vincent.guittot@linaro.org>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Morten.Rasmussen@arm.com
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: bsegall@google.com
Cc: dietmar.eggemann@arm.com
Cc: linaro-kernel@lists.linaro.org
Cc: pjt@google.com
Cc: yuyang.du@intel.com
Link: http://lkml.kernel.org/r/1473666472-13749-8-git-send-email-vincent.guittot@linaro.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
select_idle_siblings() is a known pain point for a number of
workloads; it either does too much or not enough and sometimes just
does plain wrong.
This rewrite attempts to address a number of issues (but sadly not
all).
The current code does an unconditional sched_domain iteration; with
the intent of finding an idle core (on SMT hardware). The problems
which this patch tries to address are:
- its pointless to look for idle cores if the machine is real busy;
at which point you're just wasting cycles.
- it's behaviour is inconsistent between SMT and !SMT hardware in
that !SMT hardware ends up doing a scan for any idle CPU in the LLC
domain, while SMT hardware does a scan for idle cores and if that
fails, falls back to a scan for idle threads on the 'target' core.
The new code replaces the sched_domain scan with 3 explicit scans:
1) search for an idle core in the LLC
2) search for an idle CPU in the LLC
3) search for an idle thread in the 'target' core
where 1 and 3 are conditional on SMT support and 1 and 2 have runtime
heuristics to skip the step.
Step 1) is conditional on sd_llc_shared->has_idle_cores; when a cpu
goes idle and sd_llc_shared->has_idle_cores is false, we scan all SMT
siblings of the CPU going idle. Similarly, we clear
sd_llc_shared->has_idle_cores when we fail to find an idle core.
Step 2) tracks the average cost of the scan and compares this to the
average idle time guestimate for the CPU doing the wakeup. There is a
significant fudge factor involved to deal with the variability of the
averages. Esp. hackbench was sensitive to this.
Step 3) is unconditional; we assume (also per step 1) that scanning
all SMT siblings in a core is 'cheap'.
With this; SMT systems gain step 2, which cures a few benchmarks --
notably one from Facebook.
One 'feature' of the sched_domain iteration, which we preserve in the
new code, is that it would start scanning from the 'target' CPU,
instead of scanning the cpumask in cpu id order. This avoids multiple
CPUs in the LLC scanning for idle to gang up and find the same CPU
quite as much. The down side is that tasks can end up hopping across
the LLC for no apparent reason.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Move the nr_busy_cpus thing from its hacky sd->parent->groups->sgc
location into the much more natural sched_domain_shared location.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Since struct sched_domain is strictly per cpu; introduce a structure
that is shared between all 'identical' sched_domains.
Limit to SD_SHARE_PKG_RESOURCES domains for now, as we'll only use it
for shared cache state; if another use comes up later we can easily
relax this.
While the sched_group's are normally shared between CPUs, these are
not natural to use when we need some shared state on a domain level --
since that would require the domain to have a parent, which is not a
given.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
There is no point in doing a call_rcu() for each domain, only do a
callback for the root sched domain and clean up the entire set in one
go.
Also make the entire call chain be called destroy_sched_domain*() to
remove confusion with the free_sched_domains() call, which does an
entirely different thing.
Both cpu_attach_domain() callers of destroy_sched_domain() can live
without the call_rcu() because at those points the sched_domain hasn't
been published yet.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Small cleanup; nothing uses the @cpu argument so make it go away.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The partial initialization of wait_queue_t in prepare_to_wait_event() looks
ugly. This was done to shrink .text, but we can simply add the new helper
which does the full initialization and shrink the compiled code a bit more.
And. This way prepare_to_wait_event() can have more users. In particular we
are ready to remove the signal_pending_state() checks from wait_bit_action_f
helpers and change __wait_on_bit_lock() to use prepare_to_wait_event().
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160906140055.GA6167@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
__wait_on_bit_lock() doesn't need abort_exclusive_wait() too. Right
now it can't use prepare_to_wait_event() (see the next change), but
it can do the additional finish_wait() if action() fails.
abort_exclusive_wait() no longer has callers, remove it.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160906140053.GA6164@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
___wait_event() doesn't really need abort_exclusive_wait(), we can simply
change prepare_to_wait_event() to remove the waiter from q->task_list if
it was interrupted.
This simplifies the code/logic, and this way prepare_to_wait_event() can
have more users, see the next change.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160908164815.GA18801@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
--
include/linux/wait.h | 7 +------
kernel/sched/wait.c | 35 +++++++++++++++++++++++++----------
2 files changed, 26 insertions(+), 16 deletions(-)
Otherwise this logic only works if mode is "compatible" with another
exclusive waiter.
If some wq has both TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE waiters,
abort_exclusive_wait() won't wait an uninterruptible waiter.
The main user is __wait_on_bit_lock() and currently it is fine but only
because TASK_KILLABLE includes TASK_UNINTERRUPTIBLE and we do not have
lock_page_interruptible() yet.
Just use TASK_NORMAL and remove the "mode" arg from abort_exclusive_wait().
Yes, this means that (say) wake_up_interruptible() can wake up the non-
interruptible waiter(s), but I think this is fine. And in fact I think
that abort_exclusive_wait() must die, see the next change.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160906140047.GA6157@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Since commit:
2159197d66 ("sched/core: Enable increased load resolution on 64-bit kernels")
we now have two different fixed point units for load:
- 'shares' in calc_cfs_shares() has 20 bit fixed point unit on 64-bit
kernels. Therefore use scale_load() on MIN_SHARES.
- 'wl' in effective_load() has 10 bit fixed point unit. Therefore use
scale_load_down() on tg->shares which has 20 bit fixed point unit on
64-bit kernels.
Signed-off-by: Dietmar Eggemann <dietmar.eggemann@arm.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/1471874441-24701-1-git-send-email-dietmar.eggemann@arm.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Current code can call set_cpu_sibling_map() and invoke sched_set_topology()
more than once (e.g. on CPU hot plug). When this happens after
sched_init_smp() has been called, we lose the NUMA topology extension to
sched_domain_topology in sched_init_numa(). This results in incorrect
topology when the sched domain is rebuilt.
This patch fixes the bug and issues warning if we call sched_set_topology()
after sched_init_smp().
Signed-off-by: Tim Chen <tim.c.chen@linux.intel.com>
Signed-off-by: Srinivas Pandruvada <srinivas.pandruvada@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: bp@suse.de
Cc: jolsa@redhat.com
Cc: rjw@rjwysocki.net
Link: http://lkml.kernel.org/r/1474485552-141429-2-git-send-email-srinivas.pandruvada@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
A while back, Paolo and Hannes sent an RFC patch adding threaded-able
napi poll loop support : (https://patchwork.ozlabs.org/patch/620657/)
The problem seems to be that softirqs are very aggressive and are often
handled by the current process, even if we are under stress and that
ksoftirqd was scheduled, so that innocent threads would have more chance
to make progress.
This patch makes sure that if ksoftirq is running, we let it
perform the softirq work.
Jonathan Corbet summarized the issue in https://lwn.net/Articles/687617/
Tested:
- NIC receiving traffic handled by CPU 0
- UDP receiver running on CPU 0, using a single UDP socket.
- Incoming flood of UDP packets targeting the UDP socket.
Before the patch, the UDP receiver could almost never get CPU cycles and
could only receive ~2,000 packets per second.
After the patch, CPU cycles are split 50/50 between user application and
ksoftirqd/0, and we can effectively read ~900,000 packets per second,
a huge improvement in DOS situation. (Note that more packets are now
dropped by the NIC itself, since the BH handlers get less CPU cycles to
drain RX ring buffer)
Since the load runs in well identified threads context, an admin can
more easily tune process scheduling parameters if needed.
Reported-by: Paolo Abeni <pabeni@redhat.com>
Reported-by: Hannes Frederic Sowa <hannes@stressinduktion.org>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: David Miller <davem@davemloft.net>
Cc: Hannes Frederic Sowa <hannes@redhat.com>
Cc: Jesper Dangaard Brouer <jbrouer@redhat.com>
Cc: Jonathan Corbet <corbet@lwn.net>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Rik van Riel <riel@redhat.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/1472665349.14381.356.camel@edumazet-glaptop3.roam.corp.google.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
4c737b41de ("cgroup: make cgroup_path() and friends behave in the
style of strlcpy()") broke error handling in proc_cgroup_show() and
cgroup_release_agent() by not handling negative return values from
cgroup_path_ns_locked(). Fix it.
Reported-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Tejun Heo <tj@kernel.org>
4c737b41de ("cgroup: make cgroup_path() and friends behave in the
style of strlcpy()") botched the conversion of proc_cpuset_show() and
broke its error handling. It made the function return 0 on failures
and fail to handle error returns from cgroup_path_ns(). Fix it.
Reported-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Tejun Heo <tj@kernel.org>
pr_info message spans two lines and the literal string is missing
a white space between words. Add the white space.
Signed-off-by: Colin Ian King <colin.king@canonical.com>
Acked-by: Ingo Molnar <mingo@kernel.org>
Acked-by: Steven Rostedt <rostedt@goodmis.org>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Suppose you have a map array value that is something like this
struct foo {
unsigned iter;
int array[SOME_CONSTANT];
};
You can easily insert this into an array, but you cannot modify the contents of
foo->array[] after the fact. This is because we have no way to verify we won't
go off the end of the array at verification time. This patch provides a start
for this work. We accomplish this by keeping track of a minimum and maximum
value a register could be while we're checking the code. Then at the time we
try to do an access into a MAP_VALUE we verify that the maximum offset into that
region is a valid access into that memory region. So in practice, code such as
this
unsigned index = 0;
if (foo->iter >= SOME_CONSTANT)
foo->iter = index;
else
index = foo->iter++;
foo->array[index] = bar;
would be allowed, as we can verify that index will always be between 0 and
SOME_CONSTANT-1. If you wish to use signed values you'll have to have an extra
check to make sure the index isn't less than 0, or do something like index %=
SOME_CONSTANT.
Signed-off-by: Josef Bacik <jbacik@fb.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
put_cpu_var takes the percpu data, not the data returned from
get_cpu_var.
This doesn't change the behavior.
Cc: Tejun Heo <tj@kernel.org>
Cc: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: Shaohua Li <shli@fb.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Acked-by: Tejun Heo <tj@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
After 7e8e385aaf ("x86/compat: Remove sys32_vm86_warning"), this
function has become unused, so we can remove it as well.
Link: http://lkml.kernel.org/r/20160617142903.3070388-1-arnd@arndb.de
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Cc: Alexander Viro <viro@zeniv.linux.org.uk>
Cc: "Theodore Ts'o" <tytso@mit.edu>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
CURRENT_TIME macro is not appropriate for filesystems as it
doesn't use the right granularity for filesystem timestamps.
Use current_time() instead.
CURRENT_TIME is also not y2038 safe.
This is also in preparation for the patch that transitions
vfs timestamps to use 64 bit time and hence make them
y2038 safe. As part of the effort current_time() will be
extended to do range checks. Hence, it is necessary for all
file system timestamps to use current_time(). Also,
current_time() will be transitioned along with vfs to be
y2038 safe.
Note that whenever a single call to current_time() is used
to change timestamps in different inodes, it is because they
share the same time granularity.
Signed-off-by: Deepa Dinamani <deepa.kernel@gmail.com>
Reviewed-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Felipe Balbi <balbi@kernel.org>
Acked-by: Steven Whitehouse <swhiteho@redhat.com>
Acked-by: Ryusuke Konishi <konishi.ryusuke@lab.ntt.co.jp>
Acked-by: David Sterba <dsterba@suse.com>
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Pull cgroup fixes from Tejun Heo:
"Three late fixes for cgroup: Two cpuset ones, one trivial and the
other pretty obscure, and a cgroup core fix for a bug which impacts
cgroup v2 namespace users"
* 'for-4.8-fixes' of git://git.kernel.org/pub/scm/linux/kernel/git/tj/cgroup:
cgroup: fix invalid controller enable rejections with cgroup namespace
cpuset: fix non static symbol warning
cpuset: handle race between CPU hotplug and cpuset_hotplug_work
This is trivial to do:
- add flags argument to simple_rename()
- check if flags doesn't have any other than RENAME_NOREPLACE
- assign simple_rename() to .rename2 instead of .rename
Filesystems converted:
hugetlbfs, ramfs, bpf.
Debugfs uses simple_rename() to implement debugfs_rename(), which is for
debugfs instances to rename files internally, not for userspace filesystem
access. For this case pass zero flags to simple_rename().
Signed-off-by: Miklos Szeredi <mszeredi@redhat.com>
Acked-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Cc: Alexei Starovoitov <ast@kernel.org>
This prevent future potential pointer leaks when an unprivileged eBPF
program will read a pointer value from its context. Even if
is_valid_access() returns a pointer type, the eBPF verifier replace it
with UNKNOWN_VALUE. The register value that contains a kernel address is
then allowed to leak. Moreover, this fix allows unprivileged eBPF
programs to use functions with (legitimate) pointer arguments.
Not an issue currently since reg_type is only set for PTR_TO_PACKET or
PTR_TO_PACKET_END in XDP and TC programs that can only be loaded as
privileged. For now, the only unprivileged eBPF program allowed is for
socket filtering and all the types from its context are UNKNOWN_VALUE.
However, this fix is important for future unprivileged eBPF programs
which could use pointers in their context.
Signed-off-by: Mickaël Salaün <mic@digikod.net>
Cc: Alexei Starovoitov <ast@kernel.org>
Cc: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
some issues. This contains one fix by me and one by Al. I'm sure that
he'll come up with more but for now I tested these patches and they
don't appear to have any negative impact on tracing.
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJX6FvrAAoJEKKk/i67LK/8EuIH/Arf6vJidYsmbe57WQp8PU3I
bldem6ePj6zgZ2ZqPlSGCs1J2DcK4Bh3lPVxdx7rRKVWSd/Zoj+i83hvObusR8M7
Qs1G92bJTvvVO3aPfiN0GvKGdKfGn45L+j0BcBauiTRKqnj3PkhOhIP2/ks0ewSk
qeq7R3xxo/FDs26AHS69Hm0PIIw7btyhXNX4GB3Il7IIA5/nUknw3C+bjVj86tYX
R4iElcHEhplgoSjKuLgNIRZGUnEFtsm/fnohYXpHacLTUKNXnTDY230x/OKc1yyB
1vOfHS/y5s3XSJ1lcgSjYeNc51lK8NiDASaptZSUnOookKSAooUTFELNzpbc0sg=
=+Fr3
-----END PGP SIGNATURE-----
Merge tag 'trace-v4.8-rc7' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace
Pull tracefs fixes from Steven Rostedt:
"Al Viro has been looking at the tracefs code, and has pointed out some
issues. This contains one fix by me and one by Al. I'm sure that
he'll come up with more but for now I tested these patches and they
don't appear to have any negative impact on tracing"
* tag 'trace-v4.8-rc7' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace:
fix memory leaks in tracing_buffers_splice_read()
tracing: Move mutex to protect against resetting of seq data
Fixes the following sparse warning:
kernel/irq/chip.c:786:1: warning:
symbol '__irq_do_set_handler' was not declared. Should it be static?
Signed-off-by: Wei Yongjun <weiyongjun1@huawei.com>
Link: http://lkml.kernel.org/r/1474817799-18676-1-git-send-email-weiyj.lk@gmail.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
The iter->seq can be reset outside the protection of the mutex. So can
reading of user data. Move the mutex up to the beginning of the function.
Fixes: d7350c3f45 ("tracing/core: make the read callbacks reentrants")
Cc: stable@vger.kernel.org # 2.6.30+
Reported-by: Al Viro <viro@ZenIV.linux.org.uk>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Pull perf fixes from Thomas Gleixner:
"Three fixlets for perf:
- add a missing NULL pointer check in the intel BTS driver
- make BTS an exclusive PMU because BTS can only handle one event at
a time
- ensure that exclusive events are limited to one PMU so that several
exclusive events can be scheduled on different PMU instances"
* 'perf-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
perf/core: Limit matching exclusive events to one PMU
perf/x86/intel/bts: Make it an exclusive PMU
perf/x86/intel/bts: Make sure debug store is valid
Pull irq fixes from Thomas Gleixner:
"Three fixes for irq core and irq chip drivers:
- Do not set the irq type if type is NONE. Fixes a boot regression
on various SoCs
- Use the proper cpu for setting up the GIC target list. Discovered
by the cpumask debugging code.
- A rather large fix for the MIPS-GIC so per cpu local interrupts
work again. This was discovered late because the code falls back
to slower timers which use normal device interrupts"
* 'irq-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
irqchip/mips-gic: Fix local interrupts
irqchip/gicv3: Silence noisy DEBUG_PER_CPU_MAPS warning
genirq: Skip chained interrupt trigger setup if type is IRQ_TYPE_NONE
On the v2 hierarchy, "cgroup.subtree_control" rejects controller
enables if the cgroup has processes in it. The enforcement of this
logic assumes that the cgroup wouldn't have any css_sets associated
with it if there are no tasks in the cgroup, which is no longer true
since a79a908fd2 ("cgroup: introduce cgroup namespaces").
When a cgroup namespace is created, it pins the css_set of the
creating task to use it as the root css_set of the namespace. This
extra reference stays as long as the namespace is around and makes
"cgroup.subtree_control" think that the namespace root cgroup is not
empty even when it is and thus reject controller enables.
Fix it by making cgroup_subtree_control() walk and test emptiness of
each css_set instead of testing whether the list_head is empty.
While at it, update the comment of cgroup_task_count() to indicate
that the returned value may be higher than the number of tasks, which
has always been true due to temporary references and doesn't break
anything.
Signed-off-by: Tejun Heo <tj@kernel.org>
Reported-by: Evgeny Vereshchagin <evvers@ya.ru>
Cc: Serge E. Hallyn <serge.hallyn@ubuntu.com>
Cc: Aditya Kali <adityakali@google.com>
Cc: Eric W. Biederman <ebiederm@xmission.com>
Cc: stable@vger.kernel.org # v4.6+
Fixes: a79a908fd2 ("cgroup: introduce cgroup namespaces")
Link: https://github.com/systemd/systemd/pull/3589#issuecomment-249089541
Call traceoff trigger after the event is recorded.
Since current traceoff trigger is called before recording
the event, we can not know what event stopped tracing.
Typical usecase of traceoff/traceon trigger is tracing
function calls and trace events between a pair of events.
For example, trace function calls between syscall entry/exit.
In that case, it is useful if we can see the return code
of the target syscall.
Link: http://lkml.kernel.org/r/147335074530.12462.4526186083406015005.stgit@devbox
Signed-off-by: Masami Hiramatsu <mhiramat@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
From: Andrey Vagin <avagin@openvz.org>
Each namespace has an owning user namespace and now there is not way
to discover these relationships.
Pid and user namepaces are hierarchical. There is no way to discover
parent-child relationships too.
Why we may want to know relationships between namespaces?
One use would be visualization, in order to understand the running
system. Another would be to answer the question: what capability does
process X have to perform operations on a resource governed by namespace
Y?
One more use-case (which usually called abnormal) is checkpoint/restart.
In CRIU we are going to dump and restore nested namespaces.
There [1] was a discussion about which interface to choose to determing
relationships between namespaces.
Eric suggested to add two ioctl-s [2]:
> Grumble, Grumble. I think this may actually a case for creating ioctls
> for these two cases. Now that random nsfs file descriptors are bind
> mountable the original reason for using proc files is not as pressing.
>
> One ioctl for the user namespace that owns a file descriptor.
> One ioctl for the parent namespace of a namespace file descriptor.
Here is an implementaions of these ioctl-s.
$ man man7/namespaces.7
...
Since Linux 4.X, the following ioctl(2) calls are supported for
namespace file descriptors. The correct syntax is:
fd = ioctl(ns_fd, ioctl_type);
where ioctl_type is one of the following:
NS_GET_USERNS
Returns a file descriptor that refers to an owning user names‐
pace.
NS_GET_PARENT
Returns a file descriptor that refers to a parent namespace.
This ioctl(2) can be used for pid and user namespaces. For
user namespaces, NS_GET_PARENT and NS_GET_USERNS have the same
meaning.
In addition to generic ioctl(2) errors, the following specific ones
can occur:
EINVAL NS_GET_PARENT was called for a nonhierarchical namespace.
EPERM The requested namespace is outside of the current namespace
scope.
[1] https://lkml.org/lkml/2016/7/6/158
[2] https://lkml.org/lkml/2016/7/9/101
Changes for v2:
* don't return ENOENT for init_user_ns and init_pid_ns. There is nothing
outside of the init namespace, so we can return EPERM in this case too.
> The fewer special cases the easier the code is to get
> correct, and the easier it is to read. // Eric
Changes for v3:
* rename ns->get_owner() to ns->owner(). get_* usually means that it
grabs a reference.
Cc: "Eric W. Biederman" <ebiederm@xmission.com>
Cc: James Bottomley <James.Bottomley@HansenPartnership.com>
Cc: "Michael Kerrisk (man-pages)" <mtk.manpages@gmail.com>
Cc: "W. Trevor King" <wking@tremily.us>
Cc: Alexander Viro <viro@zeniv.linux.org.uk>
Cc: Serge Hallyn <serge.hallyn@canonical.com>
Pid and user namepaces are hierarchical. There is no way to discover
parent-child relationships.
In a future we will use this interface to dump and restore nested
namespaces.
Acked-by: Serge Hallyn <serge@hallyn.com>
Signed-off-by: Andrei Vagin <avagin@openvz.org>
Signed-off-by: Eric W. Biederman <ebiederm@xmission.com>
Return -EPERM if an owning user namespace is outside of a process
current user namespace.
v2: In a first version ns_get_owner returned ENOENT for init_user_ns.
This special cases was removed from this version. There is nothing
outside of init_user_ns, so we can return EPERM.
v3: rename ns->get_owner() to ns->owner(). get_* usually means that it
grabs a reference.
Acked-by: Serge Hallyn <serge@hallyn.com>
Signed-off-by: Andrei Vagin <avagin@openvz.org>
Signed-off-by: Eric W. Biederman <ebiederm@xmission.com>
virtio-gpu is used for VMs, so add it to the kvm config.
Signed-off-by: Rob Herring <robh@kernel.org>
Cc: Christoffer Dall <christoffer.dall@linaro.org>
Cc: Marc Zyngier <marc.zyngier@arm.com>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: "Radim Krčmář" <rkrcmar@redhat.com>
Cc: kvmarm@lists.cs.columbia.edu
Cc: kvm@vger.kernel.org
[expanded "frag" to "fragment" in summary]
Signed-off-by: Radim Krčmář <rkrcmar@redhat.com>
kvm_guest.config is useful for KVM guests on other arches, and nothing
in it appears to be x86 specific, so just move the whole file. Kbuild
will find it in either location.
Signed-off-by: Rob Herring <robh@kernel.org>
Cc: Christoffer Dall <christoffer.dall@linaro.org>
Cc: Marc Zyngier <marc.zyngier@arm.com>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: "Radim Krčmář" <rkrcmar@redhat.com>
Cc: kvmarm@lists.cs.columbia.edu
Cc: kvm@vger.kernel.org
Acked-by: Christoffer Dall <christoffer.dall@linaro.org>
Signed-off-by: Radim Krčmář <rkrcmar@redhat.com>
The current error codes returned when a the per user per user
namespace limit are hit (EINVAL, EUSERS, and ENFILE) are wrong. I
asked for advice on linux-api and it we made clear that those were
the wrong error code, but a correct effor code was not suggested.
The best general error code I have found for hitting a resource limit
is ENOSPC. It is not perfect but as it is unambiguous it will serve
until someone comes up with a better error code.
Signed-off-by: "Eric W. Biederman" <ebiederm@xmission.com>
It is now unused, remove it before someone else thinks its a good idea
to use this.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
stop_two_cpus() and stop_cpus() use stop_cpus_lock to avoid the deadlock,
we need to ensure that the stopper functions can't be queued "backwards"
from one another. This doesn't look nice; if we use lglock then we do not
really need stopper->lock, cpu_stop_queue_work() could use lg_local_lock()
under local_irq_save().
OTOH it would be even better to avoid lglock in stop_machine.c and remove
lg_double_lock(). This patch adds "bool stop_cpus_in_progress" set/cleared
by queue_stop_cpus_work(), and changes cpu_stop_queue_two_works() to busy
wait until it is cleared.
queue_stop_cpus_work() sets stop_cpus_in_progress = T lockless, but after
it queues a work on CPU1 it must be visible to stop_two_cpus(CPU1, CPU2)
which checks it under the same lock. And since stop_two_cpus() holds the
2nd lock too, queue_stop_cpus_work() can not clear stop_cpus_in_progress
if it is also going to queue a work on CPU2, it needs to take that 2nd
lock to do this.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Rik van Riel <riel@redhat.com>
Cc: Tejun Heo <tj@kernel.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20151121181148.GA433@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
SCHED_HRTICK feature is useful to preempt SCHED_FAIR tasks on-the-dot
(just when they would have exceeded their ideal_runtime).
It makes use of a per-CPU hrtimer resource and hence arming that
hrtimer should be based on total SCHED_FAIR tasks a CPU has across its
various cfs_rqs, rather than being based on number of tasks in a
particular cfs_rq (as implemented currently).
As a result, with current code, its possible for a running task (which
is the sole task in its cfs_rq) to be preempted much after its
ideal_runtime has elapsed, resulting in increased latency for tasks in
other cfs_rq on same CPU.
Fix this by arming sched hrtimer based on total number of SCHED_FAIR
tasks a CPU has across its various cfs_rqs.
Signed-off-by: Srivatsa Vaddagiri <vatsa@codeaurora.org>
Signed-off-by: Joonwoo Park <joonwoop@codeaurora.org>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/1474075731-11550-1-git-send-email-joonwoop@codeaurora.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
An "exclusive" PMU is the one that can only have one event scheduled in
at any given time. There may be more than one of such PMUs in a system,
though, like Intel PT and BTS. It should be allowed to have one event
for either of those inside the same context (there may be other constraints
that may prevent this, but those would be hardware-specific). However,
the exclusivity code is written so that only one event from any of the
"exclusive" PMUs is allowed in a context.
Fix this by making the exclusive event filter explicitly match two events'
PMUs.
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Acked-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160920154811.3255-3-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
On fully preemptible kernels _cond_resched() is pointless, so avoid
emitting any code for it.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mikulas Patocka <mpatocka@redhat.com>
Cc: Oleg Nesterov <oleg@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Oleg noted that by making do_exit() use __schedule() for the TASK_DEAD
context switch, we can avoid the TASK_DEAD special case currently in
__schedule() because that avoids the extra preempt_disable() from
schedule().
In order to facilitate this, create a do_task_dead() helper which we
place in the scheduler code, such that it can access __schedule().
Also add some __noreturn annotations to the functions, there's no
coming back from do_exit().
Suggested-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Cheng Chao <cs.os.kernel@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: akpm@linux-foundation.org
Cc: chris@chris-wilson.co.uk
Cc: tj@kernel.org
Link: http://lkml.kernel.org/r/20160913163729.GB5012@twins.programming.kicks-ass.net
Signed-off-by: Ingo Molnar <mingo@kernel.org>
In case @cpu == smp_proccessor_id(), we can avoid a sleep+wakeup
cycle by doing a preemption.
Callers such as sched_exec() can benefit from this change.
Signed-off-by: Cheng Chao <cs.os.kernel@gmail.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Oleg Nesterov <oleg@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: akpm@linux-foundation.org
Cc: chris@chris-wilson.co.uk
Cc: tj@kernel.org
Link: http://lkml.kernel.org/r/1473818510-6779-1-git-send-email-cs.os.kernel@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The SMP IPI struct descriptor is allocated on the stack except for the
workqueue and lockdep complains:
INFO: trying to register non-static key.
the code is fine but needs lockdep annotation.
turning off the locking correctness validator.
CPU: 0 PID: 110 Comm: kworker/0:1 Not tainted 4.8.0-rc5+ #14
Hardware name: Dell Inc. Precision T3600/0PTTT9, BIOS A13 05/11/2014
Workqueue: events smp_call_on_cpu_callback
...
Call Trace:
dump_stack
register_lock_class
? __lock_acquire
__lock_acquire
? __lock_acquire
lock_acquire
? process_one_work
process_one_work
? process_one_work
worker_thread
? process_one_work
? process_one_work
kthread
? kthread_create_on_node
ret_from_fork
So allocate it on the stack too.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
[ Test and write commit message. ]
Signed-off-by: Borislav Petkov <bp@suse.de>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160911084323.jhtnpb4b37t5tlno@pd.tnic
Signed-off-by: Ingo Molnar <mingo@kernel.org>
We should not be using smp_processor_id() with preempt enabled.
Bug identified and fix provided by Alfred Chen.
Reported-by: Alfred Chen <cchalpha@gmail.com>
Signed-off-by: Con Kolivas <kernel@kolivas.org>
Cc: Alfred Chen <cchalpha@gmail.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/2042051.3vvUWIM0vs@hex
Signed-off-by: Ingo Molnar <mingo@kernel.org>
When running as parser interpret BPF_LD | BPF_IMM | BPF_DW
instructions as loading CONST_IMM with the value stored
in imm. The verifier will continue not recognizing those
due to concerns about search space/program complexity
increase.
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Acked-by: Daniel Borkmann <daniel@iogearbox.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
Advanced JIT compilers and translators may want to use
eBPF verifier as a base for parsers or to perform custom
checks and validations.
Add ability for external users to invoke the verifier
and provide callbacks to be invoked for every intruction
checked. For now only add most basic callback for
per-instruction pre-interpretation checks is added. More
advanced users may also like to have per-instruction post
callback and state comparison callback.
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Move verifier's internal structures to a header file and
prefix their names with bpf_ to avoid potential namespace
conflicts. Those structures will soon be used by external
analyzers.
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Acked-by: Daniel Borkmann <daniel@iogearbox.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
Storing state in reserved fields of instructions makes
it impossible to run verifier on programs already
marked as read-only. Allocate and use an array of
per-instruction state instead.
While touching the error path rename and move existing
jump target.
Suggested-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Acked-by: Daniel Borkmann <daniel@iogearbox.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
This work implements direct packet access for helpers and direct packet
write in a similar fashion as already available for XDP types via commits
4acf6c0b84 ("bpf: enable direct packet data write for xdp progs") and
6841de8b0d ("bpf: allow helpers access the packet directly"), and as a
complementary feature to the already available direct packet read for tc
(cls/act) programs.
For enabling this, we need to introduce two helpers, bpf_skb_pull_data()
and bpf_csum_update(). The first is generally needed for both, read and
write, because they would otherwise only be limited to the current linear
skb head. Usually, when the data_end test fails, programs just bail out,
or, in the direct read case, use bpf_skb_load_bytes() as an alternative
to overcome this limitation. If such data sits in non-linear parts, we
can just pull them in once with the new helper, retest and eventually
access them.
At the same time, this also makes sure the skb is uncloned, which is, of
course, a necessary condition for direct write. As this needs to be an
invariant for the write part only, the verifier detects writes and adds
a prologue that is calling bpf_skb_pull_data() to effectively unclone the
skb from the very beginning in case it is indeed cloned. The heuristic
makes use of a similar trick that was done in 233577a220 ("net: filter:
constify detection of pkt_type_offset"). This comes at zero cost for other
programs that do not use the direct write feature. Should a program use
this feature only sparsely and has read access for the most parts with,
for example, drop return codes, then such write action can be delegated
to a tail called program for mitigating this cost of potential uncloning
to a late point in time where it would have been paid similarly with the
bpf_skb_store_bytes() as well. Advantage of direct write is that the
writes are inlined whereas the helper cannot make any length assumptions
and thus needs to generate a call to memcpy() also for small sizes, as well
as cost of helper call itself with sanity checks are avoided. Plus, when
direct read is already used, we don't need to cache or perform rechecks
on the data boundaries (due to verifier invalidating previous checks for
helpers that change skb->data), so more complex programs using rewrites
can benefit from switching to direct read plus write.
For direct packet access to helpers, we save the otherwise needed copy into
a temp struct sitting on stack memory when use-case allows. Both facilities
are enabled via may_access_direct_pkt_data() in verifier. For now, we limit
this to map helpers and csum_diff, and can successively enable other helpers
where we find it makes sense. Helpers that definitely cannot be allowed for
this are those part of bpf_helper_changes_skb_data() since they can change
underlying data, and those that write into memory as this could happen for
packet typed args when still cloned. bpf_csum_update() helper accommodates
for the fact that we need to fixup checksum_complete when using direct write
instead of bpf_skb_store_bytes(), meaning the programs can use available
helpers like bpf_csum_diff(), and implement csum_add(), csum_sub(),
csum_block_add(), csum_block_sub() equivalents in eBPF together with the
new helper. A usage example will be provided for iproute2's examples/bpf/
directory.
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Current contract for the following two helper argument types is:
* ARG_CONST_STACK_SIZE: passed argument pair must be (ptr, >0).
* ARG_CONST_STACK_SIZE_OR_ZERO: passed argument pair can be either
(NULL, 0) or (ptr, >0).
With 6841de8b0d ("bpf: allow helpers access the packet directly"), we can
pass also raw packet data to helpers, so depending on the argument type
being PTR_TO_PACKET, we now either assert memory via check_packet_access()
or check_stack_boundary(). As a result, the tests in check_packet_access()
currently allow more than intended with regards to reg->imm.
Back in 969bf05eb3 ("bpf: direct packet access"), check_packet_access()
was fine to ignore size argument since in check_mem_access() size was
bpf_size_to_bytes() derived and prior to the call to check_packet_access()
guaranteed to be larger than zero.
However, for the above two argument types, it currently means, we can have
a <= 0 size and thus breaking current guarantees for helpers. Enforce a
check for size <= 0 and bail out if so.
check_stack_boundary() doesn't have such an issue since it already tests
for access_size <= 0 and bails out, resp. access_size == 0 in case of NULL
pointer passed when allowed.
Fixes: 6841de8b0d ("bpf: allow helpers access the packet directly")
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
When a socket is cloned, the associated sock_cgroup_data is duplicated
but not its reference on the cgroup. As a result, the cgroup reference
count will underflow when both sockets are destroyed later on.
Fixes: bd1060a1d6 ("sock, cgroup: add sock->sk_cgroup")
Link: http://lkml.kernel.org/r/20160914194846.11153-2-hannes@cmpxchg.org
Signed-off-by: Johannes Weiner <hannes@cmpxchg.org>
Acked-by: Tejun Heo <tj@kernel.org>
Cc: Michal Hocko <mhocko@suse.cz>
Cc: Vladimir Davydov <vdavydov@virtuozzo.com>
Cc: <stable@vger.kernel.org> [4.5+]
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Install the callbacks via the state machine. CPU-hotplug multinstance support
is used with the nocalls() version. Maybe parts of padata_alloc() could be
moved into the online callback so that we could invoke ->startup callback for
instance and drop get_online_cpus().
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Steffen Klassert <steffen.klassert@secunet.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: linux-crypto@vger.kernel.org
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160906170457.32393-14-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
There is no point in trying to configure the trigger of a chained
interrupt if no trigger information has been configured. At best
this is ignored, and at the worse this confuses the underlying
irqchip (which is likely not to handle such a thing), and
unnecessarily alarms the user.
Only apply the configuration if type is not IRQ_TYPE_NONE.
Fixes: 1e12c4a939 ("genirq: Correctly configure the trigger on chained interrupts")
Reported-and-tested-by: Geert Uytterhoeven <geert@linux-m68k.org>
Signed-off-by: Marc Zyngier <marc.zyngier@arm.com>
Link: https://lkml.kernel.org/r/CAMuHMdVW1eTn20=EtYcJ8hkVwohaSuH_yQXrY2MGBEvZ8fpFOg@mail.gmail.com
Link: http://lkml.kernel.org/r/1474274967-15984-1-git-send-email-marc.zyngier@arm.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Fixes the following sparse warning:
kernel/cpuset.c:2088:6: warning:
symbol 'cpuset_fork' was not declared. Should it be static?
Signed-off-by: Wei Yongjun <weiyongjun1@huawei.com>
Signed-off-by: Tejun Heo <tj@kernel.org>
vmalloc() is a bit slow, and pounding vmalloc()/vfree() will eventually
force a global TLB flush.
To reduce pressure on them, if CONFIG_VMAP_STACK=y, cache two thread
stacks per CPU. This will let us quickly allocate a hopefully
cache-hot, TLB-hot stack under heavy forking workloads (shell script style).
On my silly pthread_create() benchmark, it saves about 2 µs per
pthread_create()+join() with CONFIG_VMAP_STACK=y.
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Jann Horn <jann@thejh.net>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/94811d8e3994b2e962f88866290017d498eb069c.1474003868.git.luto@kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
We currently keep every task's stack around until the task_struct
itself is freed. This means that we keep the stack allocation alive
for longer than necessary and that, under load, we free stacks in
big batches whenever RCU drops the last task reference. Neither of
these is good for reuse of cache-hot memory, and freeing in batches
prevents us from usefully caching small numbers of vmalloced stacks.
On architectures that have thread_info on the stack, we can't easily
change this, but on architectures that set THREAD_INFO_IN_TASK, we
can free it as soon as the task is dead.
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Jann Horn <jann@thejh.net>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Oleg Nesterov <oleg@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/08ca06cde00ebed0046c5d26cbbf3fbb7ef5b812.1474003868.git.luto@kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
get_task_struct(tsk) no longer pins tsk->stack so all users of
to_live_kthread() should do try_get_task_stack/put_task_stack to protect
"struct kthread" which lives on kthread's stack.
TODO: Kill to_live_kthread(), perhaps we can even kill "struct kthread" too,
and rework kthread_stop(), it can use task_work_add() to sync with the exiting
kernel thread.
Message-Id: <20160629180357.GA7178@redhat.com>
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Jann Horn <jann@thejh.net>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/cb9b16bbc19d4aea4507ab0552e4644c1211d130.1474003868.git.luto@kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Pull RCU changes from Paul E. McKenney:
- Expedited grace-period changes, most notably avoiding having
user threads drive expedited grace periods, using a workqueue
instead.
- Miscellaneous fixes, including a performance fix for lists
that was sent with the lists modifications (second URL below).
- CPU hotplug updates, most notably providing exact CPU-online
tracking for RCU. This will in turn allow removal of the
checks supporting RCU's prior heuristic that was based on the
assumption that CPUs would take no longer than one jiffy to
come online.
- Torture-test updates.
- Documentation updates.
Signed-off-by: Ingo Molnar <mingo@kernel.org>
If an arch opts in by setting CONFIG_THREAD_INFO_IN_TASK_STRUCT,
then thread_info is defined as a single 'u32 flags' and is the first
entry of task_struct. thread_info::task is removed (it serves no
purpose if thread_info is embedded in task_struct), and
thread_info::cpu gets its own slot in task_struct.
This is heavily based on a patch written by Linus.
Originally-from: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Jann Horn <jann@thejh.net>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/a0898196f0476195ca02713691a5037a14f2aac5.1473801993.git.luto@kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The current irq spreading infrastructure is just looking at a cpumask and
tries to spread the interrupts over the mask. Thats suboptimal as it does
not take numa nodes into account.
Change the logic so the interrupts are spread across numa nodes and inside
the nodes. If there are more cpus than vectors per node, then we set the
affinity to several cpus. If HT siblings are available we take that into
account and try to set all siblings to a single vector.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Christoph Hellwig <hch@lst.de>
Cc: axboe@fb.com
Cc: keith.busch@intel.com
Cc: agordeev@redhat.com
Cc: linux-block@vger.kernel.org
Link: http://lkml.kernel.org/r/1473862739-15032-3-git-send-email-hch@lst.de
For irq spreading want to store affinity masks in the msi_entry. Add the
infrastructure for it.
We allocate an array of cpumasks with an array size of the number of used
vectors in the entry, so we can hand in the information per linux interrupt
later.
As we hand in the number of used vectors, we assign them right
away. Convert all the call sites.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Cc: axboe@fb.com
Cc: keith.busch@intel.com
Cc: agordeev@redhat.com
Cc: linux-block@vger.kernel.org
Cc: Christoph Hellwig <hch@lst.de>
Link: http://lkml.kernel.org/r/1473862739-15032-2-git-send-email-hch@lst.de
Introduce new flags that defines which ABI to use on creating sigframe.
Those flags kernel will set according to sigaction syscall ABI,
which set handler for the signal being delivered.
So that will drop the dependency on TIF_IA32/TIF_X32 flags on signal deliver.
Those flags will be used only under CONFIG_COMPAT.
Similar way ARM uses sa_flags to differ in which mode deliver signal
for 26-bit applications (look at SA_THIRYTWO).
Signed-off-by: Dmitry Safonov <dsafonov@virtuozzo.com>
Reviewed-by: Andy Lutomirski <luto@kernel.org>
Cc: 0x7f454c46@gmail.com
Cc: oleg@redhat.com
Cc: linux-mm@kvack.org
Cc: gorcunov@openvz.org
Cc: xemul@virtuozzo.com
Link: http://lkml.kernel.org/r/20160905133308.28234-7-dsafonov@virtuozzo.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
- ACPI IORT core code
- IORT support for the GICv3 ITS
- A few of GIC cleanups
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQIcBAABAgAGBQJX2VxlAAoJECPQ0LrRPXpD7tMP/i696FakX2xYknlVNaBy5vww
eH1TLVpItkcfUCHbOyNzJcLcVVRnC4JuaiCphtgDQ0Zm4HJsl8LRFoKF9iBF/Wmt
CvL5YLfkl6ziMZyPa23a9ApH5gKTY2QzirDAl+noF+N6tSsmz5JCXArW0YFawZJs
o1tmh/XX0xb9cqB5f/jISxTNF7rPw/Dc1sDY3/p7DUch2TDjuTLOQljnJ2EFb8Mh
QltBs9EbklYCKaSBVIHXmhAOBCaW8Nwm2BNscgNEQAH1EtjBjGK/aqmFqGzxBWms
wXr8GHSNhnVsgpOzalG6yJzhtWcj4KNf1utZaNc0L8dT1bVc0yJEEUkxOEbi4pIO
sst+BWo2FAe/cDyWWxwiSBLaO7M5SCTvsBN25AYMfZw9AU6pw6SMCdbm6BCWSPmh
YUW7khrXObtNTl+0lroi/mlmIE3sq+UVpQWDzfwsvfWb1kgqIif2Fd6TqU+Jodl5
pK/UzMHP3YQnAZjcn6Yz4sEWkAGgK8RrIPje1Th0mxi20pyx8VbAucwfSCUi5hza
9mbaaidnLRvDVX38TNs/LzOejwfW3JKDJUPy9jLg3l07Fgron+jfLtCZOEm9XfJH
nj/MN3g+yil9OeosJ+6NfzZKonJrfccpkVKkZrNT+ReeM5YFQylgX0OHRQT9eUDo
z3P5/VhsoTcyqynxMcRp
=Xhg0
-----END PGP SIGNATURE-----
Merge tag 'irqchip-4.9-1' of git://git.kernel.org/pub/scm/linux/kernel/git/maz/arm-platforms into irq/core
Merge the first drop of irqchip updates for 4.9 from Marc Zyngier:
- ACPI IORT core code
- IORT support for the GICv3 ITS
- A few of GIC cleanups
Information about interrupts is exposed via /proc/interrupts, but the
format of that file has changed over kernel versions and differs across
architectures. It also has varying column numbers depending on hardware.
That all makes it hard for tools to parse.
To solve this, expose the information through sysfs so each irq attribute
is in a separate file in a consistent, machine parsable way.
This feature is only available when both CONFIG_SPARSE_IRQ and
CONFIG_SYSFS are enabled.
Examples:
/sys/kernel/irq/18/actions: i801_smbus,ehci_hcd:usb1,uhci_hcd:usb7
/sys/kernel/irq/18/chip_name: IR-IO-APIC
/sys/kernel/irq/18/hwirq: 18
/sys/kernel/irq/18/name: fasteoi
/sys/kernel/irq/18/per_cpu_count: 0,0
/sys/kernel/irq/18/type: level
/sys/kernel/irq/25/actions: ahci0
/sys/kernel/irq/25/chip_name: IR-PCI-MSI
/sys/kernel/irq/25/hwirq: 512000
/sys/kernel/irq/25/name: edge
/sys/kernel/irq/25/per_cpu_count: 29036,0
/sys/kernel/irq/25/type: edge
[ tglx: Moved kobject_del() under sparse_irq_lock, massaged code comments
and changelog ]
Signed-off-by: Craig Gallek <kraig@google.com>
Cc: David Decotigny <decot@google.com>
Link: http://lkml.kernel.org/r/1473783291-122873-1-git-send-email-kraigatgoog@gmail.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Modify the schedutil cpufreq governor to boost the CPU
frequency if the SCHED_CPUFREQ_IOWAIT flag is passed to
it via cpufreq_update_util().
If that happens, the frequency is set to the maximum during
the first update after receiving the SCHED_CPUFREQ_IOWAIT flag
and then the boost is reduced by half during each following update.
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
Looks-good-to: Steve Muckle <smuckle@linaro.org>
Acked-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Testing indicates that it is possible to improve performace
significantly without increasing energy consumption too much by
teaching cpufreq governors to bump up the CPU performance level if
the in_iowait flag is set for the task in enqueue_task_fair().
For this purpose, define a new cpufreq_update_util() flag
SCHED_CPUFREQ_IOWAIT and modify enqueue_task_fair() to pass that
flag to cpufreq_update_util() in the in_iowait case. That generally
requires cpufreq_update_util() to be called directly from there,
because update_load_avg() may not be invoked in that case.
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
Looks-good-to: Steve Muckle <smuckle@linaro.org>
Acked-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Pull scheduler fix from Ingo Molnar:
"A try_to_wake_up() memory ordering race fix causing a busy-loop in
ttwu()"
* 'sched-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
sched/core: Fix a race between try_to_wake_up() and a woken up task
Pull perf fixes from Ingo Molnar:
"This contains:
- a set of fixes found by directed-random perf fuzzing efforts by
Vince Weaver, Alexander Shishkin and Peter Zijlstra
- a cqm driver crash fix
- an AMD uncore driver use after free fix"
* 'perf-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
perf/x86/intel: Fix PEBSv3 record drain
perf/x86/intel/bts: Kill a silly warning
perf/x86/intel/bts: Fix BTS PMI detection
perf/x86/intel/bts: Fix confused ordering of PMU callbacks
perf/core: Fix aux_mmap_count vs aux_refcount order
perf/core: Fix a race between mmap_close() and set_output() of AUX events
perf/x86/amd/uncore: Prevent use after free
perf/x86/intel/cqm: Check cqm/mbm enabled state in event init
perf/core: Remove WARN from perf_event_read()
can_stop_full_tick() has no check for offline cpus. So it allows to stop
the tick on an offline cpu from the interrupt return path, which is wrong
and subsequently makes irq_work_needs_cpu() warn about being called for an
offline cpu.
Commit f7ea0fd639 ("tick: Don't invoke tick_nohz_stop_sched_tick() if
the cpu is offline") added prevention for can_stop_idle_tick(), but forgot
to do the same in can_stop_full_tick(). Add it.
[ tglx: Massaged changelog ]
Signed-off-by: Wanpeng Li <wanpeng.li@hotmail.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Frederic Weisbecker <fweisbec@gmail.com>
Link: http://lkml.kernel.org/r/1473245473-4463-1-git-send-email-wanpeng.li@hotmail.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
A discrepancy between cpu_online_mask and cpuset's effective_cpus
mask is inevitable during hotplug since cpuset defers updating of
effective_cpus mask using a workqueue, during which time nothing
prevents the system from more hotplug operations. For that reason
guarantee_online_cpus() walks up the cpuset hierarchy until it finds
an intersection under the assumption that top cpuset's effective_cpus
mask intersects with cpu_online_mask even with such a race occurring.
However a sequence of CPU hotplugs can open a time window, during which
none of the effective CPUs in the top cpuset intersect with
cpu_online_mask.
For example when there are 4 possible CPUs 0-3 and only CPU0 is online:
======================== ===========================
cpu_online_mask top_cpuset.effective_cpus
======================== ===========================
echo 1 > cpu2/online.
CPU hotplug notifier woke up hotplug work but not yet scheduled.
[0,2] [0]
echo 0 > cpu0/online.
The workqueue is still runnable.
[2] [0]
======================== ===========================
Now there is no intersection between cpu_online_mask and
top_cpuset.effective_cpus. Thus invoking sys_sched_setaffinity() at
this moment can cause following:
Unable to handle kernel NULL pointer dereference at virtual address 000000d0
------------[ cut here ]------------
Kernel BUG at ffffffc0001389b0 [verbose debug info unavailable]
Internal error: Oops - BUG: 96000005 [#1] PREEMPT SMP
Modules linked in:
CPU: 2 PID: 1420 Comm: taskset Tainted: G W 4.4.8+ #98
task: ffffffc06a5c4880 ti: ffffffc06e124000 task.ti: ffffffc06e124000
PC is at guarantee_online_cpus+0x2c/0x58
LR is at cpuset_cpus_allowed+0x4c/0x6c
<snip>
Process taskset (pid: 1420, stack limit = 0xffffffc06e124020)
Call trace:
[<ffffffc0001389b0>] guarantee_online_cpus+0x2c/0x58
[<ffffffc00013b208>] cpuset_cpus_allowed+0x4c/0x6c
[<ffffffc0000d61f0>] sched_setaffinity+0xc0/0x1ac
[<ffffffc0000d6374>] SyS_sched_setaffinity+0x98/0xac
[<ffffffc000085cb0>] el0_svc_naked+0x24/0x28
The top cpuset's effective_cpus are guaranteed to be identical to
cpu_online_mask eventually. Hence fall back to cpu_online_mask when
there is no intersection between top cpuset's effective_cpus and
cpu_online_mask.
Signed-off-by: Joonwoo Park <joonwoop@codeaurora.org>
Acked-by: Li Zefan <lizefan@huawei.com>
Cc: Tejun Heo <tj@kernel.org>
Cc: cgroups@vger.kernel.org
Cc: linux-kernel@vger.kernel.org
Cc: <stable@vger.kernel.org> # 3.17+
Signed-off-by: Tejun Heo <tj@kernel.org>
Guenter Roeck reported breakage on the h8300 and c6x architectures (among
others) caused by the new memory protection keys syscalls. This patch does
what Arnd suggested and adds them to kernel/sys_ni.c.
Fixes: a60f7b69d9 ("generic syscalls: Wire up memory protection keys syscalls")
Reported-and-tested-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Dave Hansen <dave.hansen@intel.com>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Cc: linux-arch@vger.kernel.org
Cc: Dave Hansen <dave@sr71.net>
Cc: linux-api@vger.kernel.org
Link: http://lkml.kernel.org/r/20160912203842.48E7AC50@viggo.jf.intel.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
PAGE_POISONING_ZERO disables zeroing new pages on alloc, they are
poisoned (zeroed) as they become available.
In the hibernate use case, free pages will appear in the system without
being cleared, left there by the loading kernel.
This patch will make sure free pages are cleared on resume when
PAGE_POISONING_ZERO is enabled. We free the pages just after resume
because we can't do it later: going through any device resume code might
allocate some memory and invalidate the free pages bitmap.
Thus we don't need to disable hibernation when PAGE_POISONING_ZERO is
enabled.
Signed-off-by: Anisse Astier <anisse@astier.eu>
Reviewed-by: Kees Cook <keescook@chromium.org>
Acked-by: Pavel Machek <pavel@ucw.cz>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
Suspend-to-idle (aka the "freeze" sleep state) is a system sleep state
in which all of the processors enter deepest possible idle state and
wait for interrupts right after suspending all the devices.
There is no hard requirement for a platform to support and register
platform specific suspend_ops to enter suspend-to-idle/freeze state.
Only deeper system sleep states like PM_SUSPEND_STANDBY and
PM_SUSPEND_MEM rely on such low level support/implementation.
suspend-to-idle can be entered as along as all the devices can be
suspended. This patch enables the support for suspend-to-idle even on
systems that don't have any low level support for deeper system sleep
states and/or don't register any platform specific suspend_ops.
Signed-off-by: Sudeep Holla <sudeep.holla@arm.com>
Tested-by: Andy Gross <andy.gross@linaro.org>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
Recently we have a new report that, the harddisk can not
resume on time due to firmware issues, and got a kernel
panic because of DPM watchdog timeout. So adjust the
default timeout from 60 to 120 to survive on this platform,
and make DPM_WATCHDOG depending on EXPERT.
Link: https://bugzilla.kernel.org/show_bug.cgi?id=117971
Suggested-by: Pavel Machek <pavel@ucw.cz>
Suggested-by: Rafael J. Wysocki <rafael@kernel.org>
Reported-by: Higuita <higuita@gmx.net>
Signed-off-by: Chen Yu <yu.c.chen@intel.com>
Acked-by: Pavel Machek <pavel@ucw.cz>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
Conflicts:
drivers/net/ethernet/mediatek/mtk_eth_soc.c
drivers/net/ethernet/qlogic/qed/qed_dcbx.c
drivers/net/phy/Kconfig
All conflicts were cases of overlapping commits.
Signed-off-by: David S. Miller <davem@davemloft.net>
The hwlat tracer uses tr->max_latency, and if it's the only tracer enabled
that uses it, the build will fail. Add max_latency and its file when the
hwlat tracer is enabled.
Link: http://lkml.kernel.org/r/d6c3b7eb-ba95-1ffa-0453-464e1e24262a@infradead.org
Reported-by: Randy Dunlap <rdunlap@infradead.org>
Tested-by: Randy Dunlap <rdunlap@infradead.org>
Acked-by: Randy Dunlap <rdunlap@infradead.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Pull libnvdimm fixes from Dan Williams:
"nvdimm fixes for v4.8, two of them are tagged for -stable:
- Fix devm_memremap_pages() to use track_pfn_insert(). Otherwise,
DAX pmd mappings end up with an uncached pgprot, and unusable
performance for the device-dax interface. The device-dax interface
appeared in 4.7 so this is tagged for -stable.
- Fix a couple VM_BUG_ON() checks in the show_smaps() path to
understand DAX pmd entries. This fix is tagged for -stable.
- Fix a mis-merge of the nfit machine-check handler to flip the
polarity of an if() to match the final version of the patch that
Vishal sent for 4.8-rc1. Without this the nfit machine check
handler never detects / inserts new 'badblocks' entries which
applications use to identify lost portions of files.
- For test purposes, fix the nvdimm_clear_poison() path to operate on
legacy / simulated nvdimm memory ranges. Without this fix a test
can set badblocks, but never clear them on these ranges.
- Fix the range checking done by dax_dev_pmd_fault(). This is not
tagged for -stable since this problem is mitigated by specifying
aligned resources at device-dax setup time.
These patches have appeared in a next release over the past week. The
recent rebase you can see in the timestamps was to drop an invalid fix
as identified by the updated device-dax unit tests [1]. The -mm
touches have an ack from Andrew"
[1]: "[ndctl PATCH 0/3] device-dax test for recent kernel bugs"
https://lists.01.org/pipermail/linux-nvdimm/2016-September/006855.html
* 'libnvdimm-fixes' of git://git.kernel.org/pub/scm/linux/kernel/git/nvdimm/nvdimm:
libnvdimm: allow legacy (e820) pmem region to clear bad blocks
nfit, mce: Fix SPA matching logic in MCE handler
mm: fix cache mode of dax pmd mappings
mm: fix show_smap() for zone_device-pmd ranges
dax: fix mapping size check
There's a bug in this commit:
97a7142f15 ("sched/fair: Make update_min_vruntime() more readable")
... when !rb_leftmost && curr we fail to advance min_vruntime.
So revert it.
Reported-by: Byungchul Park <byungchul.park@lge.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The order of accesses to ring buffer's aux_mmap_count and aux_refcount
has to be preserved across the users, namely perf_mmap_close() and
perf_aux_output_begin(), otherwise the inversion can result in the latter
holding the last reference to the aux buffer and subsequently free'ing
it in atomic context, triggering a warning.
> ------------[ cut here ]------------
> WARNING: CPU: 0 PID: 257 at kernel/events/ring_buffer.c:541 __rb_free_aux+0x11a/0x130
> CPU: 0 PID: 257 Comm: stopbug Not tainted 4.8.0-rc1+ #2596
> Call Trace:
> [<ffffffff810f3e0b>] __warn+0xcb/0xf0
> [<ffffffff810f3f3d>] warn_slowpath_null+0x1d/0x20
> [<ffffffff8121182a>] __rb_free_aux+0x11a/0x130
> [<ffffffff812127a8>] rb_free_aux+0x18/0x20
> [<ffffffff81212913>] perf_aux_output_begin+0x163/0x1e0
> [<ffffffff8100c33a>] bts_event_start+0x3a/0xd0
> [<ffffffff8100c42d>] bts_event_add+0x5d/0x80
> [<ffffffff81203646>] event_sched_in.isra.104+0xf6/0x2f0
> [<ffffffff8120652e>] group_sched_in+0x6e/0x190
> [<ffffffff8120694e>] ctx_sched_in+0x2fe/0x5f0
> [<ffffffff81206ca0>] perf_event_sched_in+0x60/0x80
> [<ffffffff81206d1b>] ctx_resched+0x5b/0x90
> [<ffffffff81207281>] __perf_event_enable+0x1e1/0x240
> [<ffffffff81200639>] event_function+0xa9/0x180
> [<ffffffff81202000>] ? perf_cgroup_attach+0x70/0x70
> [<ffffffff8120203f>] remote_function+0x3f/0x50
> [<ffffffff811971f3>] flush_smp_call_function_queue+0x83/0x150
> [<ffffffff81197bd3>] generic_smp_call_function_single_interrupt+0x13/0x60
> [<ffffffff810a6477>] smp_call_function_single_interrupt+0x27/0x40
> [<ffffffff81a26ea9>] call_function_single_interrupt+0x89/0x90
> [<ffffffff81120056>] finish_task_switch+0xa6/0x210
> [<ffffffff81120017>] ? finish_task_switch+0x67/0x210
> [<ffffffff81a1e83d>] __schedule+0x3dd/0xb50
> [<ffffffff81a1efe5>] schedule+0x35/0x80
> [<ffffffff81128031>] sys_sched_yield+0x61/0x70
> [<ffffffff81a25be5>] entry_SYSCALL_64_fastpath+0x18/0xa8
> ---[ end trace 6235f556f5ea83a9 ]---
This patch puts the checks in perf_aux_output_begin() in the same order
as that of perf_mmap_close().
Reported-by: Vince Weaver <vincent.weaver@maine.edu>
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-3-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
In the mmap_close() path we need to stop all the AUX events that are
writing data to the AUX area that we are unmapping, before we can
safely free the pages. To determine if an event needs to be stopped,
we're comparing its ->rb against the one that's getting unmapped.
However, a SET_OUTPUT ioctl may turn up inside an AUX transaction
and swizzle event::rb to some other ring buffer, but the transaction
will keep writing data to the old ring buffer until the event gets
scheduled out. At this point, mmap_close() will skip over such an
event and will proceed to free the AUX area, while it's still being
used by this event, which will set off a warning in the mmap_close()
path and cause a memory corruption.
To avoid this, always stop an AUX event before its ->rb is updated;
this will release the (potentially) last reference on the AUX area
of the buffer. If the event gets restarted, its new ring buffer will
be used. If another SET_OUTPUT comes and switches it back to the
old ring buffer that's getting unmapped, it's also fine: this
ring buffer's aux_mmap_count will be zero and AUX transactions won't
start any more.
Reported-by: Vince Weaver <vincent.weaver@maine.edu>
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-2-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
This work adds BPF_CALL_<n>() macros and converts all the eBPF helper functions
to use them, in a similar fashion like we do with SYSCALL_DEFINE<n>() macros
that are used today. Motivation for this is to hide all the register handling
and all necessary casts from the user, so that it is done automatically in the
background when adding a BPF_CALL_<n>() call.
This makes current helpers easier to review, eases to write future helpers,
avoids getting the casting mess wrong, and allows for extending all helpers at
once (f.e. build time checks, etc). It also helps detecting more easily in
code reviews that unused registers are not instrumented in the code by accident,
breaking compatibility with existing programs.
BPF_CALL_<n>() internals are quite similar to SYSCALL_DEFINE<n>() ones with some
fundamental differences, for example, for generating the actual helper function
that carries all u64 regs, we need to fill unused regs, so that we always end up
with 5 u64 regs as an argument.
I reviewed several 0-5 generated BPF_CALL_<n>() variants of the .i results and
they look all as expected. No sparse issue spotted. We let this also sit for a
few days with Fengguang's kbuild test robot, and there were no issues seen. On
s390, it barked on the "uses dynamic stack allocation" notice, which is an old
one from bpf_perf_event_output{,_tp}() reappearing here due to the conversion
to the call wrapper, just telling that the perf raw record/frag sits on stack
(gcc with s390's -mwarn-dynamicstack), but that's all. Did various runtime tests
and they were fine as well. All eBPF helpers are now converted to use these
macros, getting rid of a good chunk of all the raw castings.
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Add BPF_SIZEOF() and BPF_FIELD_SIZEOF() macros to improve the code a bit
which otherwise often result in overly long bytes_to_bpf_size(sizeof())
and bytes_to_bpf_size(FIELD_SIZEOF()) lines. So place them into a macro
helper instead. Moreover, we currently have a BUILD_BUG_ON(BPF_FIELD_SIZEOF())
check in convert_bpf_extensions(), but we should rather make that generic
as well and add a BUILD_BUG_ON() test in all BPF_SIZEOF()/BPF_FIELD_SIZEOF()
users to detect any rewriter size issues at compile time. Note, there are
currently none, but we want to assert that it stays this way.
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Some minor misc cleanups, f.e. use sizeof(__u32) instead of hardcoding
and in __bpf_skb_max_len(), I missed that we always have skb->dev valid
anyway, so we can drop the unneeded test for dev; also few more other
misc bits addressed here.
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
track_pfn_insert() in vmf_insert_pfn_pmd() is marking dax mappings as
uncacheable rendering them impractical for application usage. DAX-pte
mappings are cached and the goal of establishing DAX-pmd mappings is to
attain more performance, not dramatically less (3 orders of magnitude).
track_pfn_insert() relies on a previous call to reserve_memtype() to
establish the expected page_cache_mode for the range. While memremap()
arranges for reserve_memtype() to be called, devm_memremap_pages() does
not. So, teach track_pfn_insert() and untrack_pfn() how to handle
tracking without a vma, and arrange for devm_memremap_pages() to
establish the write-back-cache reservation in the memtype tree.
Cc: <stable@vger.kernel.org>
Cc: Matthew Wilcox <mawilcox@microsoft.com>
Cc: Ross Zwisler <ross.zwisler@linux.intel.com>
Cc: Nilesh Choudhury <nilesh.choudhury@oracle.com>
Cc: Kirill A. Shutemov <kirill.shutemov@linux.intel.com>
Reported-by: Toshi Kani <toshi.kani@hpe.com>
Reported-by: Kai Zhang <kai.ka.zhang@oracle.com>
Acked-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
LLVM can generate code that tests for direct packet access via
skb->data/data_end in a way that currently gets rejected by the
verifier, example:
[...]
7: (61) r3 = *(u32 *)(r6 +80)
8: (61) r9 = *(u32 *)(r6 +76)
9: (bf) r2 = r9
10: (07) r2 += 54
11: (3d) if r3 >= r2 goto pc+12
R1=inv R2=pkt(id=0,off=54,r=0) R3=pkt_end R4=inv R6=ctx
R9=pkt(id=0,off=0,r=0) R10=fp
12: (18) r4 = 0xffffff7a
14: (05) goto pc+430
[...]
from 11 to 24: R1=inv R2=pkt(id=0,off=54,r=0) R3=pkt_end R4=inv
R6=ctx R9=pkt(id=0,off=0,r=0) R10=fp
24: (7b) *(u64 *)(r10 -40) = r1
25: (b7) r1 = 0
26: (63) *(u32 *)(r6 +56) = r1
27: (b7) r2 = 40
28: (71) r8 = *(u8 *)(r9 +20)
invalid access to packet, off=20 size=1, R9(id=0,off=0,r=0)
The reason why this gets rejected despite a proper test is that we
currently call find_good_pkt_pointers() only in case where we detect
tests like rX > pkt_end, where rX is of type pkt(id=Y,off=Z,r=0) and
derived, for example, from a register of type pkt(id=Y,off=0,r=0)
pointing to skb->data. find_good_pkt_pointers() then fills the range
in the current branch to pkt(id=Y,off=0,r=Z) on success.
For above case, we need to extend that to recognize pkt_end >= rX
pattern and mark the other branch that is taken on success with the
appropriate pkt(id=Y,off=0,r=Z) type via find_good_pkt_pointers().
Since eBPF operates on BPF_JGT (>) and BPF_JGE (>=), these are the
only two practical options to test for from what LLVM could have
generated, since there's no such thing as BPF_JLT (<) or BPF_JLE (<=)
that we would need to take into account as well.
After the fix:
[...]
7: (61) r3 = *(u32 *)(r6 +80)
8: (61) r9 = *(u32 *)(r6 +76)
9: (bf) r2 = r9
10: (07) r2 += 54
11: (3d) if r3 >= r2 goto pc+12
R1=inv R2=pkt(id=0,off=54,r=0) R3=pkt_end R4=inv R6=ctx
R9=pkt(id=0,off=0,r=0) R10=fp
12: (18) r4 = 0xffffff7a
14: (05) goto pc+430
[...]
from 11 to 24: R1=inv R2=pkt(id=0,off=54,r=54) R3=pkt_end R4=inv
R6=ctx R9=pkt(id=0,off=0,r=54) R10=fp
24: (7b) *(u64 *)(r10 -40) = r1
25: (b7) r1 = 0
26: (63) *(u32 *)(r6 +56) = r1
27: (b7) r2 = 40
28: (71) r8 = *(u8 *)(r9 +20)
29: (bf) r1 = r8
30: (25) if r8 > 0x3c goto pc+47
R1=inv56 R2=imm40 R3=pkt_end R4=inv R6=ctx R8=inv56
R9=pkt(id=0,off=0,r=54) R10=fp
31: (b7) r1 = 1
[...]
Verifier test cases are also added in this work, one that demonstrates
the mentioned example here and one that tries a bad packet access for
the current/fall-through branch (the one with types pkt(id=X,off=Y,r=0),
pkt(id=X,off=0,r=0)), then a case with good and bad accesses, and two
with both test variants (>, >=).
Fixes: 969bf05eb3 ("bpf: direct packet access")
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
The newly added bpf_overflow_handler function is only built of both
CONFIG_EVENT_TRACING and CONFIG_BPF_SYSCALL are enabled, but the caller
only checks the latter:
kernel/events/core.c: In function 'perf_event_alloc':
kernel/events/core.c:9106:27: error: 'bpf_overflow_handler' undeclared (first use in this function)
This changes the caller so we also skip this call if CONFIG_EVENT_TRACING
is disabled entirely.
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Fixes: aa6a5f3cb2 ("perf, bpf: add perf events core support for BPF_PROG_TYPE_PERF_EVENT programs")
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Install the callbacks via the state machine.
Signed-off-by: Richard Weinberger <richard@nod.at>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Reviewed-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Pekka Enberg <penberg@kernel.org>
Cc: linux-mm@kvack.org
Cc: rt@linutronix.de
Cc: David Rientjes <rientjes@google.com>
Cc: Joonsoo Kim <iamjoonsoo.kim@lge.com>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Christoph Lameter <cl@linux.com>
Link: http://lkml.kernel.org/r/20160823125319.abeapfjapf2kfezp@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Install the callbacks via the state machine. They are installed at run time but
relay_prepare_cpu() does not need to be invoked by the boot CPU because
relay_open() was not yet invoked and there are no pools that need to be created.
Signed-off-by: Richard Weinberger <richard@nod.at>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Reviewed-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: rt@linutronix.de
Cc: Andrew Morton <akpm@linux-foundation.org>
Link: http://lkml.kernel.org/r/20160818125731.27256-3-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
relay essentially needs to maintain a per CPU array of channel buffer
pointers but it manually creates that array. Instead its better to use
the per CPU constructs, provided by the kernel, to allocate & access the
array of pointer to channel buffers.
Signed-off-by: Akash Goel <akash.goel@intel.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Link: http://lkml.kernel.org/r/1470909140-25919-1-git-send-email-akash.goel@intel.com
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
All users are converted to state machine, remove CPU_STARTING and the
corresponding CPU_DYING.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160818125731.27256-2-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Some callers of __irq_set_trigger() masks all flags except trigger mode
flags. This is unnecessary, ase __irq_set_trigger() already does this
before usage of flags.
[ tglx: Moved the flag mask and adjusted comment. Removed the hunk in
enable_percpu_irq() as it is required there ]
Signed-off-by: Alexander Kuleshov <kuleshovmail@gmail.com>
Link: http://lkml.kernel.org/r/20160719095408.13778-1-kuleshovmail@gmail.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Add some more comments and reformat existing ones to kernel doc style.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Reviewed-by: Darren Hart <dvhart@linux.intel.com>
Link: http://lkml.kernel.org/r/1464770609-30168-1-git-send-email-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
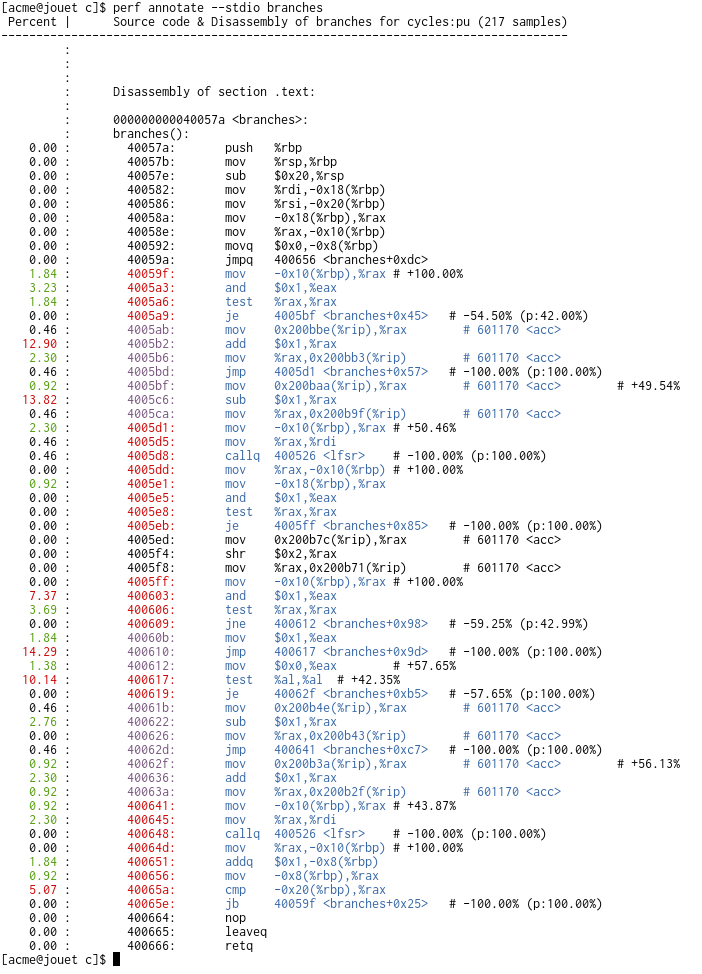{kind=link}